

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、フリーランスをやっていると直接「社長さん」や「決定権の高い方」とお話させていただく機会があり、いつも勉強になっています。
そして、この間も生成AIについて話していたところ、とある社長さんが
企業は、ChatGPTじゃなく社内で独自AIをつかうようになる
とおっしゃっていました。
というのも、企業側からすると
社外秘のデータを外に出したくないから!
だそうです。
※なんなら、会社でChatGPTが禁止なのに、こっそり使う社員もいるようです…便利ですもんね😅
実際に私もPerplexityをつかっていますが、以下のような情報は「****」みたいに伏せ字にして使っています。(エラー内容に入ってきちゃうんですよね…)
- APIキー
- 各種パスワード
- パス(URL)
- ファイル名
だったら「ローカル環境の独自AIをつかって、社外秘データも使えるようにしよう」という考えですね。
そこで!
今回は、オープンソースの「Ollama」をつかってローカル環境(=オフライン)で生成AIがつかえるようにしてみました。
機能としては「どんなLinuxコマンドをつかえばいいか教えてくれるAI」、つまり、コマンドをつかってコマンドの提案をさせるというものです。
以下のような方は、ぜひ最後まで読んでくださいね!
- 「社外秘のデータを生成AIに使いたい」
- 「ChatGPTが禁止なのに、社員は裏で使ってる状況を改善したい」
- 「クラウドAIは流出リスクが高いと思ってる」
- 「ライバル企業より、セキュアな環境で差別化したい」
- 「先進的な企業としてアピールしたい」
- 「エラーログを解析したいが、ChatGPTには送りたくない」
- 「社員の個人情報を含むデータをAIで解析したい」
- 「オフライン環境でもAIを使えるようにしたい」
- 「Linuxサーバーでも独自AIを動かしたい」

「あぶねっ!メモリ価格あがる前に
サブのパソコン買って良かった👍」
目次
前提として
今回は、サーバーでの用途を想定してので、紹介するのはUbuntu(Linux)での実装です。
※ただし、Ollamaはwindowsでも使えるので、インストール方法だけ変更すれば、いけると思います!
また、GPUなど環境によってはうまく動かないパターンも想定されます。今回はCPUでも動くとされるモデルを使いますが、適宜ご自身の状況にあわせてください🙇✨
ローカルLLMをインストールする
Ollamaのインストール方法
以下のコマンドを実行する、ただそれだけ!(私もびっくりしました😊)
curl -fsSL https://ollama.com/install.sh | sh
(ちょっと時間はかかりますが)これでダウンロードなど全部いい感じでインストールをしてくれます。
なお、Ollamaをインストールするとサービスとして追加されるので、もし毎回自動的に起動されるのが嫌なら、以下のコマンドを実行しておくといいでしょう。
sudo systemctl disable ollama
※このコマンドはUbuntuを想定しています。べつのLinuxの場合、環境にあわせてください。
モデルのインストール方法
現状ではまだ、Ollamaがインストールされただけで、生成AIとして使えません。
モデルのインストールが必要だからですね。
そこで、以下のコマンドをつかって今回は2B(パラメータが約20億)のものをインストールします。
ollama pull gemma2:2b
ちなみに、私のGPU環境にあわせて、2Bにしていますが、マシンスペックによってはもっと多くてもいいかもしれません。(2Bは、CPUでもいけるみたいです👍)
※基本的にパラメータ数が多いほうが、精度の高い回答が得られるようです。
もし、他のモデルをインストールしたい場合はOllamaのLibraryをチェックしてくださいね。
では、この状態ですでにローカルで生成AIが使えます。
以下のコマンドで起動してためしてみましょう!
ollama run gemma2:2b
以下の質問をしてみました。
こんにちは。あなたは何ができますか?
すると、返ってきた回答がこちらです!
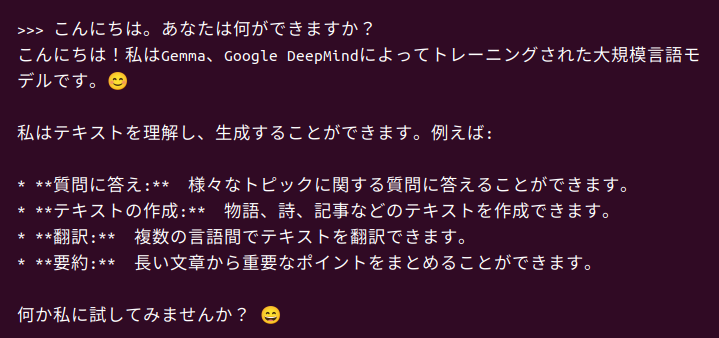
わーお!ちゃんと日本語で答えてくれますし、何なら初期のChatGPTぐらいの能力はありそうな雰囲気です。
※ちなみにLaravelとCakePHPはどっちがおすすめかを聞いたら、どちらもメリットを出してくれるなど精度の高さを感じました。また、回答の速度はべらぼうに早かったです👍
独自コマンド「ai-cmd」をつくる(Python)
では、Ollamaをつかって「どんなLinuxコマンドを使えばいいか?」を教えてくれる独自コマンド「ai-cmd」をつくります。
まずは以下のコードを「ai-cmd」として保存してください(注意:通常は必要ですが、今回は拡張子「.py」は不要です)
#!/usr/bin/env python3
import sys
import textwrap
import requests
MODEL = "gemma2:2b"
API_URL = "http://127.0.0.1:11434/api/generate"
def call_ollama(prompt: str) -> str:
payload = {
"model": MODEL,
"prompt": prompt,
"stream": False,
}
resp = requests.post(API_URL, json=payload, timeout=60)
resp.raise_for_status()
return resp.json().get("response", "").strip()
def main():
if len(sys.argv) < 2:
print("Usage: ai-cmd \"Linuxコマンドを提案する\"")
sys.exit(1)
user_request = " ".join(sys.argv[1:])
prompt = textwrap.dedent(f"""
あなたはLinuxコマンドのアシスタントです。
ユーザーの要望に対して、1行のLinuxコマンドだけを出力してください。
シェルはbashを想定してください。
危険なコマンド(rm -rf / やフォークボムなど)は絶対に出力しないでください。
ユーザーの要望:
{user_request}
""")
cmd = call_ollama(prompt)
print(cmd)
if __name__ == "__main__":
main()
※今回とは関係ないですが、PythonもTypeScriptのように型を重視するようになったんですね。シンプルなのが売りだったのに…まぁ、生成AIを使う場合はあったほうがベターですけどね!
※一応、プロンプトには危険なコマンドを提案しないように書いてます。ただ、ハルシネーション(ウソ情報)が発生する場合もありますし、本番で使う場合は、Python内でバリデーションをかけたほうがいいでしょう。
次に、これをどこからでも実行できるようにします。
chmod +x ai-cmd
sudo mv ai-cmd /usr/local/bin/
これで、どのフォルダにいても「ai-cmd」が使えるようになりました!
おまけ:実は、Laravelからでも使える!
Pythonのコードを見て気づいた方もいるかもですが、実はOllamaはHTTP、つまりウェブからアクセスができるようになっています。
つまり!Laravelからでもローカルの生成AIにアクセスすることができるんですね。
ということで、やってみました。
環境:Laravel 12.x + Vue 3(ts) + Inertia
routes/web.php
Route::get('/ollama', [OllamaController::class, 'index'])->name('ollama.index');
Route::post('/ollama', [OllamaController::class, 'store'])->name('ollama.store');
app/Http/Controllers/OllamaController.php
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use Illuminate\Http\JsonResponse;
use Illuminate\Support\Facades\Http;
use Inertia\Inertia;
class OllamaController extends Controller
{
const MODEL = 'gemma2:2b';
public function index()
{
return Inertia::render('Ollama/Index');
}
public function store(Request $request): JsonResponse
{
// バリデーションは省略しています
$url = 'http://127.0.0.1:11434/api/generate';
$payload = array_merge($request->all(), [
'model' => self::MODEL,
'stream' => false,
]);
try {
$response = Http::timeout(60)
->withHeaders(['Content-Type' => 'application/json', 'Accept' => 'application/json'])
->post($url, $payload);
if ($response->successful()) {
$body = $response->body();
$decoded = json_decode($body, true);
return response()->json([
'response' => $decoded['response'] ?? '',
]);
}
} catch (\Exception $e) {}
abort(500);
}
}
resources/js/Pages/Ollama/Index.vue
<template>
<div class="mx-auto max-w-3xl p-6">
<h1 class="mb-4 text-2xl font-bold">LaravelからOllama APIを呼び出す</h1>
<form @submit.prevent="submit" class="space-y-4">
<div>
<label class="block text-sm font-medium text-gray-700"
>プロンプト</label
>
<textarea
v-model="form.prompt"
rows="6"
class="mt-1 block w-full rounded-md border-gray-300 shadow-sm focus:border-indigo-500 focus:ring-indigo-500"
></textarea>
</div>
<div class="flex items-center space-x-3">
<button
type="submit"
:disabled="loading"
class="inline-flex items-center rounded-md bg-indigo-600 px-4 py-2 text-white hover:bg-indigo-700 disabled:opacity-60"
>
<svg
v-if="loading"
class="-ml-1 mr-2 h-5 w-5 animate-spin text-white"
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 24 24"
>
<circle
class="opacity-25"
cx="12"
cy="12"
r="10"
stroke="currentColor"
stroke-width="4"
></circle>
<path
class="opacity-75"
fill="currentColor"
d="M4 12a8 8 0 018-8v4a4 4 0 00-4 4H4z"
></path>
</svg>
<span>{{ loading ? '生成中…' : '送信' }}</span>
</button>
<button
type="button"
@click="clear"
class="rounded-md border px-4 py-2"
>
クリア
</button>
<div v-if="error" class="text-red-600">{{ error }}</div>
</div>
</form>
<div v-if="response" class="mt-6 rounded-md border bg-gray-50 p-4">
<h2 class="mb-2 font-semibold">Ollamaの回答</h2>
<pre class="whitespace-pre-wrap">{{ response }}</pre>
</div>
</div>
</template>
<script lang="ts">
import axios from 'axios';
import { defineComponent, reactive, ref } from 'vue';
interface OllamaResponse {
response?: string | null;
}
export default defineComponent({
setup() {
const form = reactive({
model: 'gemma2:2b',
prompt: '',
});
const loading = ref(false);
const response = ref<string | null>(null);
const error = ref<string | null>(null);
const submit = async () => {
error.value = null;
response.value = null;
loading.value = true;
try {
const res = await axios.post<OllamaResponse>('/ollama', {
model: form.model,
prompt: form.prompt,
});
const data = res.data;
const text = String(data.response ?? '');
response.value = text.trim();
} catch (e: any) {
error.value =
e?.response?.data?.error || e.message || 'Unknown error';
} finally {
loading.value = false;
}
};
const clear = () => {
form.prompt = '';
response.value = null;
error.value = null;
};
return { form, loading, response, error, submit, clear };
},
});
</script>
テストしてみる
では、実際にテストしてみましょう!
今回はダウンロードフォルダに移動して、以下のコマンドを実行してみます。
ai-cmd "このフォルダの直下から、ファイル名にPXLが含まれているものをリストアップしたい"
すると・・・・・・
```bash
find . -type f -name "*PXL*"
```
回答してくれました!
しかも、マークダウンで返してくれました。
では、提案されたコマンドを実行してみましょう。
find . -type f -name "*PXL*"
うまくいくでしょうか・・・・・・
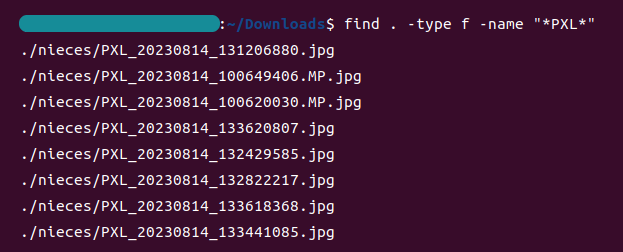
はい!
提案されたコマンドで目的のファイルをリストアップすることができました。
ちなみに、おまけでつくったLaravelの実行結果はこんな感じです!
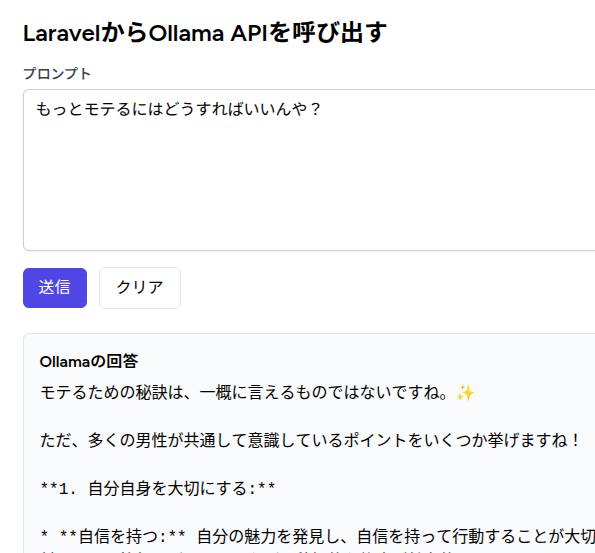
「自身を持つ」とか、なかなかしっかりした回答ですね(笑)
すべて成功です😊✨
企業様へのご提案
ChatGPTやGeminiのような超高性能なものとはいきませんが、シンプルな回答なら、ローカル環境で生成AIをつかうことができます。
つまり、社外秘の情報でいくら質問しても、外部にもれることはありません。
そのため、たとえば顧客の個人情報をつかって解析をする場合でも、安心して業務を進めることができます。
しかも、今回使用したOllamaはオープンソースなので、無料で使えますし、実行環境のスペックが良ければ、より高性能なモデルを使うこともできます。
もし社外秘データをつかって生成AIを使いたいなどのご相談がありましたら、お問い合わせからご相談ください。
お待ちしております😊
おわりに
ということで、今回はローカルLLMをつかってサポートコマンドをつくってみました!
正直言うと、最初は「オープンソースのAIなんて、レベル低くて使えないっしょ…😊」ぐらいに思ってましたが、使ってみると「あれ、普通に賢いぞ!」って印象でした。
ちなみに、私が長らく使ってるphpstormでも「モデルをダウンロードして、オフラインでコード補完できる」サービスを始めていますし、ローカルLLMの流れが確実にあるような気がしています。
これって、お買い物で言うと、
- 街まで行かなきゃいけなかった
- 近くにコンビニができた
- もう家でAmazonでポチればいい
っていう感じで、より身近になる流れに似てますね。
こんな感じで変化が早い時代ですが、AIやAIをつかったロボット、核融合発電などが進化し続けると、ホントに働く必要がない時代がく来るのでしょうか🤔
過渡期は、いろいろ混乱もありそうですが、未来がどんな世界になるか楽しみですね。
ではでは〜!

「働かなくて良くなっても、好きだから、
パソコンでカタカタやってるはず(笑)」





