九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、実はこのブログではできるだけ直近の記事と関連のある記事をお届けするようにしているのですが、何かそんな内容がないかと考えていたところ1つ思い浮かびました。
それは、前々回の【Vue】wordpressのRest APIからデータを取得して一覧表示するという記事に関連する内容なのですが、この内容は「コンテンツをJavaScriptでレンダリングする」というものになっています。
そして、今回のテーマは、この
JavaScriptでレンダリングされたコンテンツをスクレイピングする
方法です。
どういうことかというと、例えばPHPでスクレイピングをしようとしても以下のようにVueで作成する内容は一切情報を取得することができません。
<ul>
<li v-for="item in items">
<a :href="item.url" v-text="item.title"></a>
</li>
</ul>
なぜなら、HTMLはJavaScript(つまりブラウザ)でその都度つくることになるからです。
※ サンプルはこちら。この中では<h1>〜</h1>以外は全てVueでコンテンツを作っています。
そして、このようなページをスクレイピングするにはLaravel + Python でウェブサイトのサムネイルをつくるでも紹介したことがある「ヘッドレスChrome」を使います。
ヘッドレスChromeとは、我々がいつも使っている「ブラウザのGoogle Chrome」ではなく、プログラム的に使う、いわば「表示をしないブラウザ」です。
ということで今回は、この「ヘッドレスChrome」でJavaScriptで作成されたコンテンツからデータを切り出す方法をご紹介します。
ぜひ皆さんのお役に立てると嬉しいです😊✨

開発環境: Ubuntu 18.04、Node.js 8.10
前提として
今回は「ヘッドレスChrome」を使う関係上Node.jsを使って開発することになりますので、まずはNode.jsが使えるようにしておいてください。
また、次の項目でパッケージをインストールするのでnpmも同じく使えるようにしておいてください。(Chrome本体はインストールしなくても大丈夫です)
パッケージをインストールする
前回はPythonでしたが、今回はNode.jsですのでnpmから「ヘッドレスChrome」が使えるpuppeteerをインストールしておきましょう。
まずは適当なフォルダにコマンドで移動してから、以下のコマンドを実行してください。
npm i puppeteer
※ ここで同じフォルダ内にChrome(正確にはchromium)もインストールされます。
やりたいこと
冒頭で紹介したサンプルページにアクセスして、
- Vueでレンダリングされた記事のURLを取得する
- また、カテゴリを変更してから再度記事のURLを取得する
という2つの機能を実装してみます。
では実際にやっていきましょう!
シンプルに記事のURLだけを取得する
まず最初はシンプルに、「ヘッドレスChrome」でページにアクセスした直後に表示される記事のURLを取得してみましょう。
puppeteerをインストールしたフォルダにget_links.jsというファイルを作成してください。
そして、中身は次のようにします。
const puppeteer = require('puppeteer');
(async () => {
const targetUrl = 'http://demo-laravel58.capilano-fw.com/wordpress_list';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(targetUrl, {
waitUntil: 'networkidle0' // Vueのレンダリングを待つ
});
const postUrls = await page.evaluate(() => {
const links = document.querySelectorAll('.link-more a'); // セレクタを指定して記事リンクを取得
let urls = [];
for(let link of links) {
urls.push(link.getAttribute('href')); // hrefの内容を取得
}
return urls;
});
console.log(postUrls); // 記事のURL
await browser.close();
})();
どうでしょう。
「ヘッドレスChrome」を使うなんて言っていたので複雑なコードが必要かと思いきや結構シンプルにできると思いませんか??
ちなみに、この中で重要なのはpage.goto()の部分です。
await page.goto(targetUrl, {
waitUntil: 'networkidle0' // Vueのレンダリングを待つ
});
この中にはwaitUntilというパラメータにnetworkidle0という設定をしていますが、これはネットワークがゼロ(つまり、Ajaxなどのアクセスをしていない)状態になるまで待ちます、という意味になります。
これは、サンプルページではまずAjaxを使ってカテゴリと記事データを取得しているので、この設定をしていないとスクレイピングが早すぎてデータが取得できないためです。
また、ところどころawaitがついていますが、これも必須です。
もしawaitをつけていない場合はJavaScriptのPromiseが返ってくることになります。
では、この時点で以下のコマンドを実行してみましょう。
nodejs get_links.js
すると以下のようになりました。
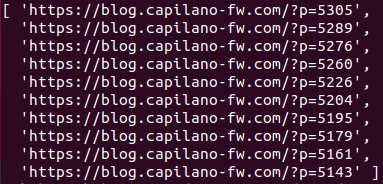
成功です😊✨
カテゴリを選択した後に記事のURLを取得する
では、続いてカテゴリを「OpenCV」に変更してから記事のURLを取得してみます。
新しいファイルget_category_links.jsを作成して中身を以下のようにしてください。(基本的に先ほどと同じですが、太字の部分が追加したところです)
const puppeteer = require('puppeteer');
(async () => {
const targetUrl = 'http://demo-laravel58.capilano-fw.com/wordpress_list';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(targetUrl, {
waitUntil: 'networkidle0' // Vueのレンダリングを待つ
});
const radioInput = await page.$('input[type="radio"][value="120"]'); // カテゴリ:OpenCV
radioInput.click();
await page.waitFor(3000); // 3秒待つ
const postUrls = await page.evaluate(() => {
const links = document.querySelectorAll('.link-more a'); // セレクタを指定して記事リンクを取得
let urls = [];
for(let link of links) {
urls.push(link.getAttribute('href')); // hrefの内容を取得
}
return urls;
});
console.log(postUrls); // 記事のURL
await browser.close();
})();
ここでは、「ヘッドレスChrome」の中でカテゴリが「OpenCV」になっているラジオボタンをクリックした後、レンダリングする時間を3秒待ってから先ほどのようにURLを取得しています。
なお、puppeteerのGitHubページではwaitForNavigationを使ってクリック後の処理を待つように言っていますが、必ずタイムアウトしてしまう(Issueにもいくつか上がっているようです)ので、今回は3秒待つ形にしました。
では実際に実行してみましょう。
nodejs get_category_links.js
結果はこうなりました。
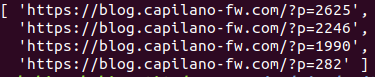
うまくいきました😊✨
おわりに
ということで「ヘッドレスChrome」とNode.jsでJavaScriptでレンダリングした内容をスクレイピングしてみました。
最近はReactやAngular、VueなどJavaScriptでレンダリングするページが増えてきていると思いますので、今回のテクニックを覚えておくと通常の開発業務だけでなく幅広い対応ができるようになると思います。
ぜひ活用してみてくださいね。
ではでは〜!
 「久しぶりに
「久しぶりにNode.jsを使って楽しかった♪」