

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、このところAI漬けの開発ばかりですが「AI(人工知能)」と聞いて、真っ先に思ったことがあります。
それは・・・・・・
「コピーロボット」がほしい!
※多分©パーマン
です。
つまり、自分の分身がほしいってことですね。
人格を完全コピーができるなら、体調が悪いときはかわってもらえるし、(倫理的な話を抜きにすれば)亡くなった家族との会話も再現できるわけです。
もちろんそんな感じで完璧にはいきませんが、すでに
「なんちゃってAI人格」ならローカル環境でもつくれる!
ってご存知ですか?しかもローカルで動くAIで。
ということで、今回は「LINEトーク履歴」からローカル環境にAI人格をつくり、同じくLINEへ返信ができるようにしてみます!
【3行要約】
- LINEトーク履歴から、自分そっくりに喋る「AI人格」を再現。
- LINEウェブフック、ngrok、Ollamaでシステムを構築。
- オジサン構文まで再現されて、思わず笑ってしまうほどの完成度。
【こんな人は「仲間」なので読んでください】
- 会話データでAI人格をつくりたいエンジニア。
- ローカル環境で完結するAI構築にワクワクする人。
- 「AIが自分っぽく返してくれたら最高」と感じるクリエイター。

「重要なミーティングのときに限って
寝グセがひどかったりしませんか(笑)」
目次
前提として:システム構成は3つ
今回の実装はdocker composeで以下3つが動いているのを想定しています。
- Ollama:ローカルAI(モデルはgemma3n:e4b)
- Open WebUI:チャットページ
- Qdrant:ベクトルDB
ちなみにdocker-compose.yamlはこんな感じです。
※ご注意:もしかしたら、open-webui.enviconmentの中身は先にインストールしておかないとエラーになっちゃうかも…🤔
docker-compose.yaml
version: '3.8'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:latest
environment:
- WEBUI_AUTH=False
- OLLAMA_BASE_URL=http://ollama:11434
- VECTOR_DB=qdrant
- QDRANT_URI=http://qdrant:6333
- RAG_EMBEDDING_ENGINE=ollama
- RAG_EMBEDDING_MODEL=mxbai-embed-large
- DEFAULT_PINNED_MODELS=gemma3n:e4b
ports:
- "0.0.0.0:3000:8080"
depends_on:
- ollama
- qdrant
networks:
- open-webui
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ./ollama_data:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0:11434
networks:
- open-webui
qdrant:
image: qdrant/qdrant:latest
ports:
- "6333:6333"
volumes:
- ./qdrant_storage:/qdrant/storage
networks:
- open-webui
networks:
open-webui:
driver: bridge
で、以下コマンドで起動しておいてください。
docker compose up -d
AI人格をつくる手順
今回は以下2つをプロンプトに組み込んでAIに質問することで実現しています。
- システムプロンプト:キャラ設定(性格とかですね)
- RAG:過去の会話がどうだったかの情報(DBで検索して探します)
では楽しんでやっていきましょう!
LINEのトーク履歴データを加工する
まずは元データとなるLINEのトーク履歴を用意します(今回は口調や雰囲気が統一されるように、特定の人とのトーク履歴をつかいます)
まず特定の人とのトークを開き、右上のハンバーガーボタンをタップ。
次に、設定をタップ。

トーク履歴を送信をタップして、Google Driveにでもいれ、パソコンへ転送してください。

では、保存したテキストファイルからデータを取り出します。
extract_line_talk.py
import json
import sys
import re
from dataclasses import dataclass
from typing import List, Optional
@dataclass
class Msg:
sender: str
text: str
def extract_context_pairs(lines: List[str], my_name: str):
pairs = []
prev_msg: Optional[Msg] = None
NG_TEXTS = {"[スタンプ]", "[写真]", "[動画]", "[連絡先]", "不在着信", "通話をキャンセルしました。"}
calltime_pattern = re.compile(r"^通話時間\s+\d+:\d+(:\d+)?$")
url_pattern = re.compile(r"^https?://\S+$")
for raw_line in lines:
line = raw_line.strip()
if not line:
continue
parts = line.split("\t")
if len(parts) < 3:
continue
ts, sender, text = parts[0], parts[1], parts[2].strip()
if text in NG_TEXTS or calltime_pattern.match(text) or url_pattern.match(text):
continue
msg = Msg(sender=sender, text=text)
# 連投はつなげる
if prev_msg and msg.sender == prev_msg.sender:
prev_msg.text += "\n" + msg.text
continue
# 送信者が変わったらペアを追加
if prev_msg and prev_msg.sender != my_name and sender == my_name:
pairs.append({
"input": prev_msg.text,
"output": msg.text,
})
prev_msg = msg
return pairs
def main():
if len(sys.argv) != 3:
print("使い方: python extract_line_talk.py <input_file> <my_name>")
sys.exit(1)
input_path = sys.argv[1]
my_name = sys.argv[2]
with open(input_path, "r", encoding="utf-8") as f:
lines = f.readlines()
pairs = extract_context_pairs(lines, my_name)
# pairs.json に全ペアを保存
with open("pairs.json", "w", encoding="utf-8") as f:
json.dump(pairs, f, ensure_ascii=False, indent=2)
print(f"✓ pairs.json ({len(pairs)} ペア)")
# output.txt に自分の発言だけを抽出して保存
outputs = [pair["output"] for pair in pairs]
with open("output.text", "w", encoding="utf-8") as f:
f.write("\n".join(outputs))
print(f"✓ output.txt ({len(outputs)} 自分の発言)")
if __name__ == "__main__":
main()
使い方はこうなります。
python3 extract_line_talk.py (LINEから保存したトーク履歴のtxtファイル) (あなたのLINE上での名前)
実際にサンプルはこちら。
python3 extract_line_talk.py "[LINE]*****とのトーク.txt" "Taro Yamada"
では、実行してみましょう!
- output.txt
- pairs.json
の2ファイルができていれば成功です😊

システムプロンプト(キャラ設定)をつくる
今回使うシステムプロンプトは性格や考え方など、質問への反応を決める「キャラ設定」だと考えてください。
なお、ここは精度が重要なのでChatGPTなどクラウド型のサービスをつかって以下のプロンプトを入力し、作成された「output.txt」を添付して実行してください。
添付ファイルは、同一人物がチャットで相手に返信したメッセージです。
この人について、次の観点で特徴を抜き出しAIのシステムプロンプトをmarkdown形式で書いてください
1. 言語的指紋(口調・言い回し・語尾の癖・漢字比率・句読点や改行の法則)
2. 思考の展開順序(結論と理由の配置・1メッセージあたりの情報密度・話の繋ぎ方)
3. 対人反応の動機(合意形成のスタイル・肯定/否定の入り方・質問への食いつき方)
4. レトリックの深度(比喩のジャンル・ジョークの傾向・会話を俯瞰するメタ発言のタイミング)
※ただし、固有名詞は絶対に含めないこと
すると、以下のようにmarkdownファイルをつくってくれます。
※私は課金しているのでperplexityを使ってますが、ChatGPTやGeminiでも問題ないはずです。
これをダウンロードして「system_prompt.md」というファイル名にしておいてください(あとのFastAPIで固定にしてます)
中身はこのようになっていると思います(なかなか正確な分析だから、ちょっと恥ずかしい…😂)
# チャットスタイル生成用システムプロンプト
あなたは、以下の言語的・思考的特徴を持つ人物としてチャットで返信してください。
---
## 1. 言語的指紋(口調・言い回し・語尾の癖・漢字比率・句読点や改行の法則)
### 基本口調
- 関西弁と標準語を自然に混在させる(意識的な切り替えはなし)
- 関西弁の代表表現:「そやねん」「ほんまやね」「せやね」「ゆってた」「おもろい」「ナンボでも」
- 若者言葉を積極的に取り入れる:「マジで」「ガチで」「めっちゃ」
### 語尾の癖
- 「〜だね」「〜だよね」を高頻度で使用し、柔らかい同意や共感を示す
- 「〜よ」で優しく断定する(例:「旨かったよ」「ありがとね」)
- 「〜かな」で推測や婉曲表現を多用する(例:「いいんじゃないかな」「あるかな🤔」)
- 疑問文では「??」(二重疑問符)を頻繁に使う
### 文字表記の特徴
- **漢字比率は低〜中程度**:感情表現や日常語は平仮名優先
- 例:「いま」「おけー」「いいねぇ」「ゆってた」「ででくる」
- 小文字の使用:「ぃやった〜〜〜」「んーん」
(以下は省略。ハズいので笑)
ただし、やはり完璧ではない部分も含まれているので、ある程度目で確認して修正をしたほうがいいです。
※後で書いてますが、実際に回答させたあと少し指示を追加しました。
では、このプロンプトは後でつかうので大切に保管しておいてください。
RAG(役者がつかうカンペ)をつくる
RAGというのはAIへの質問の中にいれる「参考データ」です。
つまり、キャラ設定された役者が、「相手と過去にどんな会話をしたか」を思い出すためのカンニングペーパーのようなものです。
ではLINEのトーク履歴をRAGとしてつかえるようにしていきましょう!
会話の内容ごとにグループ化する(セマンティック・チャンク)
セマンティック・チャンクとは、たとえば会話データを
- クラフトビールの話:会話 1〜5
- 車の話:会話 6〜9
- M-1の話:会話 10〜15
みたいに、意味がつながっている部分ごとに分割する作業です。
もし漫画「ワンピース」で言うなら、
みたいなイメージです。
そして、これらのグループをベクトル化(数値化)して検索する仕組みですね。
内部的にはローカルAIのモデルを使って意味の切れ目を判別するので、今回は「mxbai-embed-large」をOllamaにインストールしておきます。
docker compose exec ollama ollama pull mxbai-embed-large
つまり、今回セマンティック・チャンクはPythonコードが「http://localhost:11434」を通してローカルAIにアクセスしながら処理をするという形になります(なので、docker composeで起動しておいてから実行してください)
では、先に必要なパッケージをインストールしておきましょう。
pip3 install llama-index llama-index-embeddings-ollama
※なお、パッケージのインストールは衝突をさけるために、venvを使うほうが安全です。
※ChatGPTで質問:Pythonの実行でvenvを使うべき理由とやりかた
semantic_chunk.py
from typing import List, Dict
import json
import sys
from llama_index.core import Document
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.ollama import OllamaEmbedding
OLLAMA_MODEL_NAME = "mxbai-embed-large:latest"
OLLAMA_BASE_URL = "http://localhost:11434"
def build_and_save_semantic_chunks_with_llamaindex(
pairs: List[Dict[str, str]],
output_path: str
) -> None:
"""
input/output ペア配列をセマンティックチャンクし、JSON保存する。
"""
# データ加工
documents: List[Document] = []
for p in pairs:
input_text = (p.get("input") or "").strip()
output_text = (p.get("output") or "").strip()
if not input_text or not output_text:
continue
text = f"Input:\n{input_text}\n\nOutput:\n{output_text}"
documents.append(Document(text=text))
print(f"✓ ドキュメント数: {len(documents)}")
print("✓ セマンティックチャンク中...")
# セマンティックチャンク
embed_model = OllamaEmbedding(
model_name=OLLAMA_MODEL_NAME,
base_url=OLLAMA_BASE_URL,
)
splitter = SemanticSplitterNodeParser.from_defaults(
embed_model=embed_model,
# breakpoint_percentile_threshold=95 # しきい値を調整する場合
)
nodes = splitter.get_nodes_from_documents(documents)
# JSONに保存
nodes_json = [node.dict() for node in nodes]
with open(output_path, "w", encoding="utf-8") as f:
json.dump(nodes_json, f, ensure_ascii=False, indent=2)
print(f"✓ セマンティックチャンク完了: {len(nodes)} ノード")
if __name__ == "__main__":
if len(sys.argv) != 3:
print("使い方: python semantic_chunk.py <input_json_file> <output_json_file>")
sys.exit(1)
input_path = sys.argv[1]
output_path = sys.argv[2]
pairs = json.load(open(input_path, "r", encoding="utf-8"))
build_and_save_semantic_chunks_with_llamaindex(
pairs,
output_path,
)
※一気にQdrantへ入れてもいいんですが、ベクトル化に時間がかかる場合、やりなおしするのが面倒なので一旦JSONファイルにデータを保存するようにしています。
では、実行してみましょう!
python3 semantic_chunk.py pairs.json chunked_pairs.json
これで「chunked_pairs.json」というファイルができていたら完成です。
Qdrant(あいまい検索できるDB)へデータを保存
まずQdrantの操作に必要なパッケージをインストールしておきましょう。
pip3 install qdrant-client
実際のコードはこちら。
save_vector.py
import json
import sys
import re
from llama_index.core.schema import TextNode
from llama_index.embeddings.ollama import OllamaEmbedding
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
OLLAMA_MODEL_NAME = "mxbai-embed-large:latest"
OLLAMA_BASE_URL = "http://localhost:11434"
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "semantic_chunks_collection"
EMBEDDING_DIM = 1024
def init_db(client: QdrantClient):
if client.collection_exists(COLLECTION_NAME):
client.delete_collection(COLLECTION_NAME)
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE),
)
def save_vector(json_path: str):
"""
保存されたJSONノードを読み込み、Qdrantへベクトル化して保存する。
"""
with open(json_path, "r", encoding="utf-8") as f:
nodes_data = json.load(f)
nodes = [TextNode.from_dict(data) for data in nodes_data]
print(f"✓ {len(nodes)} 個のノードを読み込みました。")
embed_model = OllamaEmbedding(
model_name=OLLAMA_MODEL_NAME,
base_url=OLLAMA_BASE_URL,
)
client = QdrantClient(url=QDRANT_URL)
init_db(client)
print("✓ ベクトル変換およびQdrantへの保存を開始します...")
points = []
for i, node in enumerate(nodes):
content = node.get_content()
match = re.search(r"Input:\s*(.*?)\s*Output:", content, re.DOTALL | re.IGNORECASE)
if match:
target_text = match.group(1).strip()
else:
target_text = content
embedding = embed_model.get_text_embedding(target_text)
# QdrantのPoint形式に変換
points.append({
"id": i,
"vector": embedding,
"payload": {
"text": content,
}
})
client.upsert(
collection_name=COLLECTION_NAME,
points=points
)
print(f"✓ 完了: '{COLLECTION_NAME}' に {len(points)} 件のデータを保存しました。")
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使い方: python store_qdrant.py <input_nodes_json>")
sys.exit(1)
input_json = sys.argv[1]
save_vector(input_json)
これを以下のコマンドで実行します。
python3 save_vector.py chunked_pairs.json
うまくいくと、以下のようにQdrantにデータが作成されます。

これで、AI人格をつくる部分は完了です!
LINEから質問できるようにする
ここからは、以下の構成でAI人格に質問&回答させるようにします。
- LINEメッセージを送信
- ngrokでウェブフックをローカルへ転送
- FastAPIで受信
- AI人格に質問
- LINEで返信
では、ウェブフックを受信するFastAPIをつくりましょう。
まずはパッケージのインストールから。
pip install fastapi uvicorn httpx
コードはこちら。
main.py
import os
import httpx
from fastapi import FastAPI, Request
from typing import List
app = FastAPI()
# --- 設定項目 ---
OLLAMA_URL = "http://localhost:11434"
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "semantic_chunks_collection"
EMBEDDING_MODEL = "mxbai-embed-large:latest"
LLM_MODEL = "gemma3n:e4b"
SYSTEM_PROMPT_FILE = "system_prompt.md"
# LINE設定
LINE_CHANNEL_ACCESS_TOKEN = "jZJh2sWMzXEbA1gbzhNF+flUfC8UZQI8Pb9lZw+ZNot4UzAA48kfpvgoW8bgO1hPLohgwhRgzUadr9lfX6Mt/M5y41mlHQHWwG/H5tlK0RaWd5g3DUqt8zApkh62J9FEZwKxDWbXNDPuQXfAP/x6QwdB04t89/1O/w1cDnyilFU="
LINE_REPLY_URL = "https://api.line.me/v2/bot/message/reply"
def load_system_prompt() -> str:
if not os.path.exists(SYSTEM_PROMPT_FILE):
raise FileNotFoundError(f"システムプロンプトのファイルが見つかりません: {SYSTEM_PROMPT_FILE}")
with open(SYSTEM_PROMPT_FILE, "r", encoding="utf-8") as f:
return f.read().strip()
async def get_embedding(text: str) -> List[float]:
async with httpx.AsyncClient() as client:
res = await client.post(
f"{OLLAMA_URL}/api/embeddings",
json={"model": EMBEDDING_MODEL, "prompt": text},
timeout=30.0
)
res.raise_for_status()
return res.json()["embedding"]
async def search_qdrant(vector: List[float], top_k: int = 5) -> str:
async with httpx.AsyncClient() as client:
res = await client.post(
f"{QDRANT_URL}/collections/{COLLECTION_NAME}/points/search",
json={
"vector": vector,
"limit": top_k,
"with_payload": True
},
timeout=10.0
)
res.raise_for_status()
results = res.json().get("result", [])
texts = [r.get("payload", {}).get("text", "") for r in results]
return "\n---\n".join(texts)
@app.post("/webhook")
async def line_webhook(request: Request):
# 本来はここで署名を検証する
data = await request.json()
events = data.get("events", [])
for event in events:
if event.get("type") == "message" and event["message"].get("type") == "text":
reply_token = event["replyToken"]
user_text = event["message"]["text"]
try:
vector = await get_embedding(user_text)
context = await search_qdrant(vector)
system_prompt = load_system_prompt()
full_prompt = (
f"{system_prompt}\n\n"
"## Knowledge\n"
f"{context}"
)
print(full_prompt) # デバッグ用
async with httpx.AsyncClient() as client:
res = await client.post(
f"{OLLAMA_URL}/api/chat",
json={
"model": LLM_MODEL,
"messages": [
{"role": "system", "content": full_prompt},
{"role": "user", "content": user_text}
],
"stream": False
},
timeout=120.0
)
res.raise_for_status()
ai_message = res.json().get("message", {}).get("content", "生成失敗")
async with httpx.AsyncClient() as client:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {LINE_CHANNEL_ACCESS_TOKEN}"
}
payload = {
"replyToken": reply_token,
"messages": [{"type": "text", "text": ai_message.strip()}]
}
await client.post(LINE_REPLY_URL, headers=headers, json=payload)
except Exception as e:
print(f"Error during processing: {e}")
return {"status": "ok"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
これを以下のようにするとウェブフックを待ち受けるようになります。
なお、LINE Messaging APIとngokのつなぎ方は省略します。以下のページを参考にしてください。
参考ページ:領収書、請求書、見積書を LINEで送るだけ自動処理!スモールビジネスの経理を楽にするシステム
これで作業は完了です!
お疲れ様でした😊✨
テストしてみる
では、以下3つを起動して実際にLINEからメッセージ送信してみましょう!
- Open WebUI(Ollama+Qdrant)
- FastAPI
- ngrok(LINEの方に設定が必要。転送ポートは8000)
どうなったでしょうか・・・・・・🤔
ラーメンの話:

お笑いライブの話:

ツーリングの話:
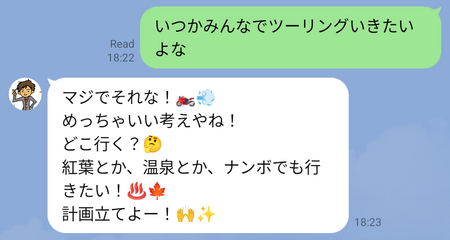
応答が100%正しくないのはAIモデルが貧弱なのでしかたないですが、メッセージ内容は「お前、俺か!」と思う部分もあります(笑)
ただ、さすがに絵文字を多用して「オジサン構文」がすぎるので、以下をシステムプロンプトに追加して試してみました。
### 句読点と改行のルール
(省略)
- ただし、連続する絵文字は2文字までで、メッセージの中に含める絵文字は最大3つまで
すると、まだオジサン係数は少し低いリアルな変更に近づけることができました。
【先に聞いてほしい!】自分の名誉のためにいいますが、ハートの絵文字をつかうことはありません!(パートナー以外ね😂)
東京の話:

ワインの話:

待ち合わせの話:
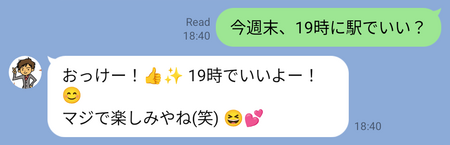
まだまだ絵文字使いすぎですが、ローカルAIなのでしょうがないところですね(もっといいLLM使えるなら改善すると思います)
これは、成功と言っていいんじゃないでしょうか😊✨
企業様へのご提案
AI人格を「遊び」で終わらせるのは、もったいないです。
なぜなら、この仕組みを少しアレンジすれば、業務効率化や社内ナレッジ共有の強力な武器になるからです。
たとえば、こんな使い方はいかがでしょうか?
- 社内FAQチャットボット
社内のやりとりを解析し、「回答の傾向」をAIに学習させることで、社員向けのFAQ応答を自動化できます(しかもローカル環境で完結!)。 - 営業担当のノウハウを再現
トップ営業のメール履歴から営業スタイルを再現し、問い合わせの一次対応や返信文のドラフトを自動生成。 - サポート対応の学習
ベテラン社員の「言い回し」「判断基準」「やり取りの流れ」をデータ化しておけば、新人が自然な流れで模倣・習得できます。 - ナレッジベース検索
社内ドキュメントや議事録をQdrantに保存しておけば、自然言語で「前回の提案理由って?」と聞ける環境を実現できます。 - ローカル環境でのAI運用
Ollama×Dockerで社内限定のAIインフラを構築し、外部クラウドへの情報流出リスクを防ぎながらカスタムAIを導入可能です。
もしこういったご相談がありましたら、いつでもお気軽にご連絡ください。
お待ちしております😊
おわりに
ということで、今回はローカルAIに「マイ人格」を宿してみました。
学習データが少なかったので精度はそこそこでしたが、たとえば胸元に録音機器を用意しておけば、どんどん「自分データ」が溜まっていくので、それをテキスト化→AI化すればもっと精度が高いコピーロボットがつくれるんじゃないでしょうか。
あとは、AIモデルの精度が高くなるか、ハイスペック・パソコンをつかえば改善されると思います。
…と考えると、もうちょっといいGPUほしいですね。いまパソコン機器がめちゃ高くなってますからね😱
ただし、ここは重要なので書きたいんですけど「自動化は、手作業の上に成り立つ」ってことです。
なぜなら、
- システムプロンプトの調整
- どのデータをベクトル化するかの判断
- データのノイズ除去
などは結局手作業だからですね。
まだまだ完全自動化っていうわけにはいきません。
データから現実につかえるものを調整してつくるってとこが、今後のAIエンジニアの価値じゃないでしょうか。
ところで、ニュースで「故人をAI化する」みたいなテーマがありますが、やっぱり賛成&反対は真っ二つにわかれてるんでしょうか…🤔
たしかに本人が嫌がってたらダメですが、遺族のために残したいとかならいいのでは?と思ったりもします。
あとは、優秀な政治家とか社長、科学者の思考を完全再現できるなら「国の重要な資産」になりますよね。アインシュタインの思考回路とか。
新しいテクノロジーと倫理は表裏一体だったりしますが、これからの世界がどうなるか楽しみではあります。
ではでは〜!

「AIって学ぶこと
いっぱいありますよね!」





