

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、このところLaravelやVue関連の記事ばかり書いていたので、たまには「9回カレーだったら、次はハヤシライス」的な気分になりました。
そして、じゃあ何がいいかなと考えていたところ過去にやってみたある内容が思い浮かびました。
それは・・・・・・
「ヘッドレス Chrome」
です。
📝 参考ページ: JavaScriptでレンダリングしてるページをスクレイピングする方法
「ヘッドレス Chrome」とは、シンプルに言うと「目に見える部分がない = 頭がない = ヘッドレス」のことで、その分高速に実行することができるため、スクレイピングなどに利用されています。
しかも、ヘッドレスとは言え、ちゃんとしたブラウザなので、なんと…
JavaScriptのレンダリングに対応している!
のがPHPのGuzzleとの大きな違いです。
そこで❗
今回はNode.jsを使って「ヘッドレス Chrome」を操作し、特定のサイトだけに絞ったクローラーをつくってみることにしました。
ぜひ何かの参考になれば嬉しいです。😊✨
 「お気に入りのビール醸造所が
「お気に入りのビール醸造所が
お気に入りだった風味のビール
を出してて感動👍」
開発環境: NodeJS v16.15.0
目次
やりたいこと
今回は「ヤフーニュース」のサイト内に「政府」という言葉が存在しているかというクローラーをつくっていきます。
※ なお、「政府」というキーワードは比較的多めに入っているようでしたので、決定しました。(ホントは「明石家さんま」が良かったんですけどね😂)
では、実際に作業をしていきましょう❗
ヘッドレス Chrome をインストールする
まずは「ヘッドレス Chrome」がないとはじまりませんので、以下のURLを参考にしてインストールを済ませておいてください。
📝 参考ページ: JavaScriptでレンダリングしてるページをスクレイピングする方法
パッケージをインストールする
今回はNodeJSからMySQLにアクセスしますので、以下のパッケージをインストールしておいてください。
npm install mysql
データベースにテーブルを用意する
では、クローラーがアクセスした時に取得することになるURLを保存するテーブルcrawler_urlsを作成します。(私の環境ではadminerを使っていますが、PhpMyAdminでも同じことができますので同じテーブル構造を作成してください)
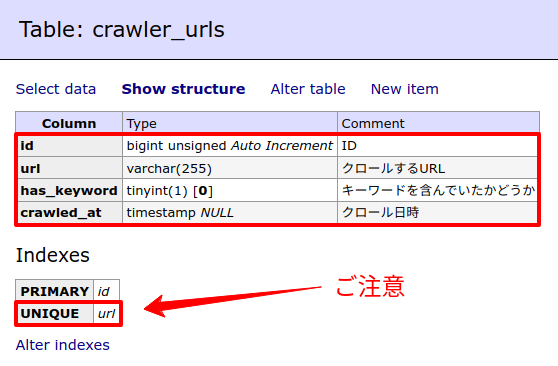
なお、以下の部分にはお気をつけください。
- has_keyword はデフォルト値に「false」がついている
- url には、UNIQUE制限がついている
(こういう作業をやると、Laravelのマイグレーションって便利だと感じますね😂)
クローラーのコードを書く
では、ここからがメインのNode.jsコードになります。
こちらです。
↓ ↓ ↓
crawler.js
// Constants
const CRAWLER_TOP_URL = 'https://news.yahoo.co.jp/'; // ヤフーニュース
const KEYWORD = '政府'; // 探したいキーワード
// DB
const mysql = require('mysql');
const util = require('util');
const { exit } = require('process');
const connection = mysql.createConnection({
host: 'localhost',
user: '(MySQL のユーザー名)',
password: '(MySQL のパスワード)',
database: 'crawler'
});
const query = util.promisify(connection.query).bind(connection);
const getCrawlerUrl = async () => {
const sql = 'SELECT * FROM crawler_urls ORDER BY RAND() LIMIT 1';
const rows = await query(sql);
if(rows.length > 0) {
return rows[0].url;
}
return CRAWLER_TOP_URL;
}
const saveCrawlerUrls = async (urls) => {
for(const url of urls) {
const sql = 'INSERT INTO crawler_urls (url) VALUES (?) ON DUPLICATE KEY UPDATE url = ?';
const values = [url, url];
await query(sql, values);
}
};
const saveHasKeyword = async (hasKeyword, url) => {
const sql = 'UPDATE crawler_urls SET has_keyword = ?, crawled_at = ? WHERE url = ?';
const values = [hasKeyword, new Date(), url];
await query(sql, values);
};
// Crawler
const puppeteer = require('puppeteer');
const url = require('url');
const getTargetHostNameUrl = targetUrls => { // ドメインが CRAWLER_TOP_URL と同じものだけ抽出
const baseHostName = url.parse(CRAWLER_TOP_URL).hostname;
return targetUrls.filter(targetUrl => {
if(! targetUrl) {
return false;
}
const hostName = url.parse(targetUrl).hostname;
return hostName === baseHostName;
});
};
(async() => {
// これからクロールする URL を DB から取得する
const crawlerUrl = await getCrawlerUrl();
console.log('Crawling URL: '+ crawlerUrl);
// ヘッドレス Chrome でアクセス
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(crawlerUrl, { waitUntil: 'networkidle0' });
const [crawlerUrls, content] = await page.evaluate(() => { // ここはブラウザ内の JavaScript
let urls = [];
document.querySelectorAll('a').forEach(link => {
const url = link.getAttribute('href');
urls.push(url);
});
const content = document.body.innerText;
return [urls, content];
})
const filteredCrawlerUrls = getTargetHostNameUrl(crawlerUrls);
// 取得した URL を DB へ保存する
await saveCrawlerUrls(filteredCrawlerUrls);
// キーワードが含まれているかチェック
const hasKeyword = content.includes(KEYWORD);
await saveHasKeyword(hasKeyword, crawlerUrl);
if(hasKeyword === true) {
console.log('キーワードが含まれています!');
}
await browser.close();
exit();
})();
この中で少しめんどうというか厄介なのが、async/await部分じゃないでしょうか。
意味としては、「非同期(async)の部分が完了するまで待つよ(await)👍」という意味になります。
そのため、非同期であっても順番にコードを実行しつつ返り値が取得できるのでコードが書きやすくなるメリットがあります。
なお、私は通常のJavaScriptではそれほど、async/awaitは使いませんが、「MySQLへの接続」や「ヘッドレス Chromeの部分」が非同期になっている関係で採用しました。
また、大きく以下のブロックで囲んでいるのは、「await は、async 関数の中でしか使えない」という制約があるためです。
(async() => { ... })();
この辺りは概念的に少し難しいかもですね…😅
テストしてみる
では、実際にテストしてみましょう❗
ターミナルからコードのある場所に移動し、以下のコマンドを何度か実行してみます。
node crawler.js
※ ご注意: 環境によっては「node」ではないかもしれません。
「政府」というキーワードが含まれているニュースは存在しているでしょうか・・・・・・
データベースはこうなりました。
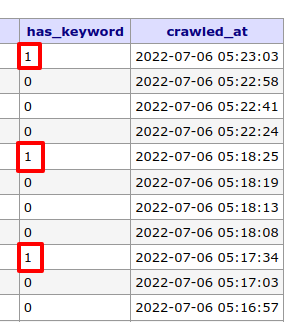
はい❗
キーワードが含まれているページとそうでないページが存在しています。
成功です😊✨(実際にURLを確認したところきちんとキーワードが含まれていました)
企業様へのご提案
今回のような独自クローラーをつくっておくことで、「情報集め」に役立てることができます。
例えば、以下のような使い方はいかがでしょうか。
- 株価に関連があるような決算のニュースをチェックする
- 自分の業界に関連のあるキーワードが含まれている記事をチェックすることでライバル会社の動向を探る
- 特定のキーワードが含まれている記事に載っている会社へ営業をかけたり、自社製品の提案をする
なにより、一番大きなメリットは上記のような作業を「全自動で繰り返し実行できる」という部分です。
そして、空いた時間はよりクリエイティブな作業にあてて、ぜひ業績を伸ばすことに役立ててください。
こういった機能をご希望でしたら、お気軽にご連絡ください。
お待ちしております。😊✨
おわりに
ということで、今回は「ヘッドレス Chrome」を使って特定サイトに特化したクローラーをつくってみました。
何気に「JavaScriptでレンダリングされたものでもOK」というは大きなメリットだと言って良いんじゃないでしょうか。
さらに、ブラウザ内にカスタムのプログラムを挿入することができるので、通常はそのサイトではできない動きを強制的に実行でき、アイデア次第でいろいろなことができそうです。
ぜひ皆さんもチャレンジしてみてくださいね。
ではでは〜❗
 「クライアントさんにいただいた
「クライアントさんにいただいた
クラフトビールがまろやかで
美味しい❗」





