

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、このブログでは【Laravel + Google vision API】ウェブカメラで名刺を読みとって会員データ入力という記事を公開しています。
これはGoogle Vision APIを使って画像から文字を取得するという内容なのですが、実はこのサービスは有料になっています。(ただし、実行回数が少なければ無料でいけますし、基本的に料金は安いです)
正直なところ、精度を問われると間違いなくこういったクラウドのサービスを使うべきだと思いますが、もしかすると「精度は落ちてもいいので無料でやりたい」という需要があるのかなとも思いましたので、今回PHPを使って画像からテキストを読み取る(OCR)を無料でできる方法を紹介することにしました。
というのも、これも以前公開したネットカフェ向けにコミックをどこまで読んだか記録するLINEボットをつくったという記事でつくったBotは、基本的にバーコードを読み取って漫画情報を取得しているのですが、どうやら講談社はコミック本体にバーコードをつけていないので、どうしたもんかと考えていたからです。(←おそらく「せどり」なんでしょうね)
そこで!
今回はPHPを使って画像から文字を読み取る方法(無料バージョン)をお届けしたいと思います。
ぜひ皆さんのお役に立てると嬉しいです😊✨

実行環境: Ubuntu 18.04、PHP 7.2
目次
OCR機能をインストールする
今回PHPを使って・・・と書きましたが、実際に画像からテキストを読み取るのは、Tesseract OCRというパッケージになります。(Apacheライセンスで使えます)
そのため、まずはこのパッケージをインストールしておきましょう。
(Ubuntuの場合)
sudo apt install tesseract-ocr sudo apt install libtesseract-dev
※ CentOSなど他のOSの場合はそれぞれのパターンでこちらにインストール方法がまとめられています。
インストールが完了したら以下のコマンドを実行してみてください。
tesseract -v
実行して次のような表示が出たらインストールはうまくいっています。
tesseract 4.0.0-beta.1 ... ... (以下省略)
Tesseract OCRをPHPから使う
Tesseract OCRはコマンドラインで実行するものですので、PHPから使うためには次のようにexec()を使います。
$path = '/YOUR/PATH/TO/IMAGE/test.jpg'; $command = '/usr/bin/tesseract "'. $path .'" stdout -l eng'; exec($command, $ocr_texts);
$ocr_textsの中に配列で取得されたテキストが入ってくることになりますので、foreach()などでひとつずつ中身を取得するといいでしょう。
なお、上の例では実際は以下のコマンドを実行することになります。
/usr/bin/tesseract "/YOUR/PATH/TO/IMAGE/test.jpg" stdout -l eng
ここで重要なのが「exec() で指定するパスは、絶対パスでないといけない」という部分です。これは、画像のパスだけでなくTesseract OCRについても同じです。
つまり、もし以下のように通常のコマンドラインの感覚で実行してもうまくいきません。
// うまくいかない例
exec('tesseract "test.jpg" stdout -l eng', $ocr_texts);
もしTesseract OCRの場所がわからないようでしたら、以下のコマンドを実行してください。絶対パスを返してくれます。
which tesseract
ISBNを取得する例
では、Tesseract OCR + PHPを使って画像からISBNを取得する例をご紹介します。
$isbn_codes = [];
$path = '/YOUR/PATH/TO/IMAGE/test.jpg';
$command = '/usr/bin/tesseract "'. $path .'" stdout -l eng';
exec($command, $ocr_texts);
foreach($ocr_texts as $ocr_text) {
if(preg_match_all('|978[0-9\-]{10,}|', $ocr_text, $matches)) { // 978ではじまる数字
foreach($matches as $match) {
$match_text = str_replace('-', '', $match[0]); // ハイフンを除去
if(strlen($match_text) === 13) { // 13桁のものだけ
$isbn_codes[] = $match_text;
}
}
}
}
print_r(array_unique($isbn_codes));
この例ではうまく画像からISBNが取得されると$isbn_codesの中にその全てが配列で格納されることになります。
なお、LINEの漫画チャットボットにもこれをベースとした同様の機能をつけてみましたので良かったら以下から試してみてください。
 「コミックのしおり」
「コミックのしおり」
OCRを日本語対応させる
今回は、Tesseract OCR(tesseract 4.0.0-beta.1)をUbuntu 18にインストールしたわけですが、初期状態では日本語には対応していません。
そのため、ここでは日本語対応させる手順を紹介します。
まず、以下2つのURL先にあるDownloadというボタンをクリックしてそれぞれファイルをダウンロードします。
- https://github.com/tesseract-ocr/tessdata_best/blob/master/jpn.traineddata
- https://github.com/tesseract-ocr/tessdata_best/blob/master/jpn_vert.traineddata
※ Tesseract OCRは、GitHubにWikiページがあって、こちらのページから言語データを取得できるようにしてくれているのですが、これは古いバージョン用のパラメータが残ってしまっているようでうまくいきません。
ダウンロードしたら、その2つのファイルを以下のフォルダに移動させます。
/usr/share/tesseract-ocr/4.00/tessdata
これで日本語対応は完了です。
以下のコマンドで確認しておきましょう。
tesseract --list-langs
うまいいっていれば、このような表示になります。
List of available languages (4): jpn_vert osd jpn eng
精度を検証してみた
ということで、ここまではTesseract OCRの実装方法を紹介してきましたが、「じゃあ、どのくらいの精度があるのか」という探究心が湧いてきたので実際の画像と一緒に抽出結果を紹介していきます。
※ なお、日本語のものは-lの言語オプションをjpnにして実行していますが、それ以外はengです。
アルファベットだけ

【実行結果】
ABCDEFGHIJKLMNOPQRSTUVWXYZ
さすがにこれは完璧でした!
数字だけ
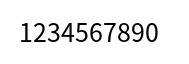
【実行結果】
1234567890
こちらも完璧です。
アルファベットの文章

フォントサイズは25で、フォントタイプはsansす。
【実行結果】
It is a fine day today!
ビックリマークまで読み取っています。
やっぱり英語のように文字の総数が少ない言語はOCRには有利ですね。
文字を小さくしてみた
![]()
フォントサイズは18です。
【実行結果】
It is a fine day today!
完璧です😊
もっともっと文字を小さくしてみた
![]()
フォントサイズは8です。
【実行結果】
his a fine day today!
おしい!
it がhになってしまいました。ただ、この大きさで大したもんです。
斜体にしてみた
![]()
先ほどの実験である程度小さい文字でも大丈夫なことがわかったのでフォントサイズは15でやっています。
【実行結果】
It is a fine day today!
完璧です。
すごいですねTesseract OCR。
色を薄くしてみた
![]()
【実行結果】
Itis a fine day today!
文字的には完璧ですが、スペースがひとつ抜けてしまいました。
※ ちなみにフォントサイズを20にすると完璧に読み取ってくれました。
日本語50音
※ ここからは、実行する言語パラメータ-lをjpnに変えて実行しています。なお、日本語化はOCRを日本語対応させるをご覧ください。

【実行結果】
あい うえ お か きく け こ さしすせそ た ち つ て と な に ぬ ね の は ひ ふ へ ほ まみ むめも や ゆ よ ら り る れろ わ を ん
元画像にスペースは入れていませんが、「い」と「う」の間のようにスペースできてしまう場合があります。
ただ、文字としては完璧に読み取っています。
漢字も入れた日本語文章

【実行結果】
今日 は いい 天気 で すね !
漢字も完璧に読み取るとは思いませんでした!
スペースは相変わらず入ってきますが、str_replace()などを使えば簡単に除去できますし、それほど問題ではないと思います。
吾輩は猫であるの冒頭部分

最後に総仕上げとして、誰でも一度は見たことがある文章で試してみましょう!
【実行結果】
吾輩 は 猫 で ある 。 名 前 は まだ 無い 。 どこ で 生れ た か と ん と 見 当 が つか ぬ 。 何 で も 薄暗い じめじめ し た 所 で ニヤ ー ニ ヤー 泣い て ゐ た 事 だ け は 記 憶 し て ゐる 。 吾 輩 は ここ で 始め て 人 間 と いふ も の を 見 た 。 し か も あと で 聞く と それ は 書生 と いふ 人 間 中 で 一 番 (猟) 悪 な 種族 で あつ た さ う だ 。 こ の 書生 と いふ の は 時 々 我々 を 捕 へ て 煮 て 食 ふ と いふ 話 で ある 。 し か し そ の 当時 は 何と いふ 考 も な か つた か ら 別 段 恐 し いと も 思 は な か つた 。
()をつけた部分が間違って読み取ったところですが、たった1ヵ所だけです。やはり画数が多い漢字は読みとりが難しいのかもしれませんね。
ただ、「。」や旧仮名遣い「ゐ」まで完璧に読みとっているのには感動しました。(「る」と区別できているのがすごいです)
ここまで実現できるとなると、本番の開発でもクライアントさんに提案できるぐらいの精度と言ってもいいのかもしれません。
※ 実行環境によりますが、この文章を取得するのに5秒ほどの時間がかかりました。そのため、スペックが低いPCやサーバーではテキストが長いと厳しいかもしれません。
おわりに
ということで今回は、PHPでOCRを実現する無料バージョンの方法をお届けしました。
実はその昔無料のOCRを試したことがあったのですが、その時はお世辞にも実用に耐えないと言わざるを得ない精度でした。
そのため、私の中で「満足できるOCR大手のサービスだけだろう・・・」と勝手に思い込んでしまっていたので、今回大変驚きました。
おそらく機械学習を使ったデータなのでしょうが、確実に科学は進歩しているんだなと実感させられましたね。
この文字読みとりを使えば、何か他にも面白い機能がつくれそうな気がします。
ぜひみなさんもご自身の開発で使ってみてくださいね。
ではでは〜!






