

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、この間数回に渡って【Python】Pasori RC-S380で入退室システムをつくるのような「リアルとPCの融合」をテーマにした記事を公開してきました。
そして、その時点では「今のところ連携したい機器も購入してないし、また機会がきたら・・・」なんて思ってたんですけど、開発に関するネットサーフィンをしているときに以下の記事を発見してしまい、どうしてもやってみたくなったので(ちょっと忙しいくせに時間を割いて)試してみることにしました。
Vision APIとNatural Language APIを組み合わせて名刺から情報抽出する
これは、タイトルの通りGoogle が提供しているVision API(画像から顔認識や分類など様々な処理ができるAPI)を使って「名刺に書かれているテキスト」を読み取るというものです。(Qiitaっていい記事多いですよね😊✨)
ただし、この記事はPythonを使っているのでPHPではこちらのコードは使えません。もちろん私もPython好きなのでそのままやってもいいのですが、「おんなじことするのも…」なんて思ったので、今回はあえてLaravel(PHP)で実装してみることにしました。
ということで今回は画像の文字を読み取るOCRをGoogle Vision APIを使ってやってみたいと思います。
ぜひ皆さんのお役に立てると嬉しいです!
(最後に今回実際に開発したソースコードをダウンロードできます)

開発環境: Laravel 5.8、Vue 2.6
目次
やりたいこと
今回開発する流れはおおまかに以下の3つです。
- PCのウェブカメラで名刺を撮影
- 画像データを送信し、Vision APIでテキストデータを抽出
- 抽出したテキストをブラウザに返し、テキストボックスに入力する
※ ちなみに今回のコードではウェブカメラにアクセスしていますがGoogle ChromeはローカルであってもHTTPS接続でないとウェブカメラにはアクセスできないようになっていますので注意してください。もしローカルにHTTPSを導入する場合は以下のページを参考にしてみてください。
コピペでOK!ローカル環境にHTTPSを導入する(nginx編)
では、実際にやっていきましょう!
Google Cloud APIの準備
まずはGoogle Cloud APIの「Vision API」が利用できるように設定をします。
まだアカウント登録していない方は登録しておいてください。
※ 有料ですが、1,000回/月までは無料です。詳しい料金はこちらのページをご覧ください。
そして、今回のために専用のプロジェクトを作成します。
作成の仕方は、以下の「プロジェクトをつくる」を参考にしてみてください。プロジェクト名は「business-card」です。
プロジェクトを作成したら次にVision APIを有効にしましょう。
まず、ページ左側にあるメニューの中から「APIとサービス > ダッシュボード」をクリックします。
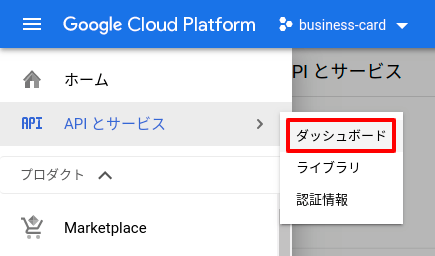
ページが移動したら、次の「+ APIとサービスを有効化」をクリック。

ライブラリの検索画面になるので「vision」と入力。
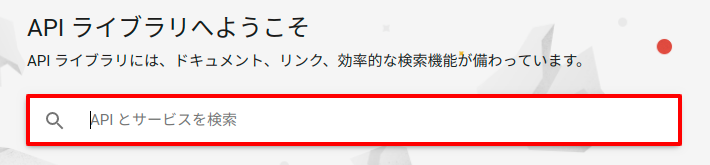
するとCloud Vision APIがリスト表示されるのでこれをクリック。

後は「有効にする」ボタンをクリックすればVision APIは有効になります。
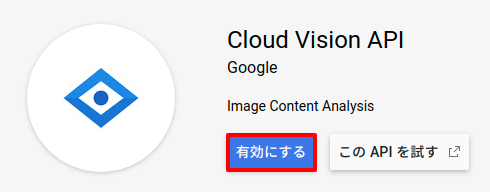
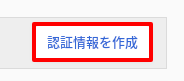
次にこのVision APIにアクセスするためのキー(JSON)を作成していきましょう。ページ右上にある「認証情報を作成」ボタンをクリックします。
使用するAPIを「Cloud Vision API」、App Engineの仕様を「いいえ」に変更して「必要な認証情報」ボタンをクリック。
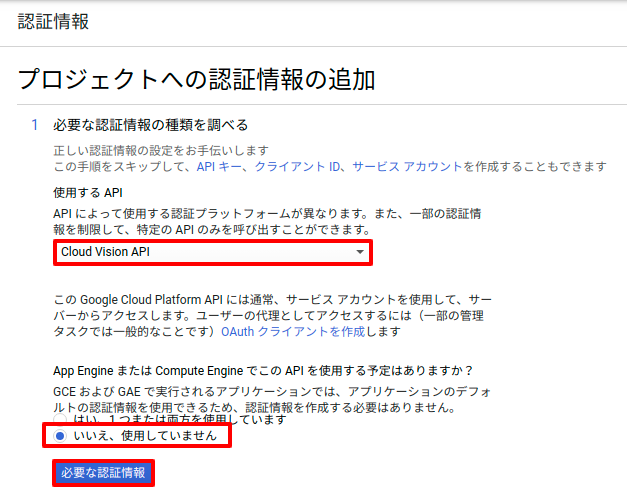
同じくサービスアカウント名に「business-card」と入力し、役割を「オーナー」。キーのタイプをJSONにして「次へ」ボタンをクリック。
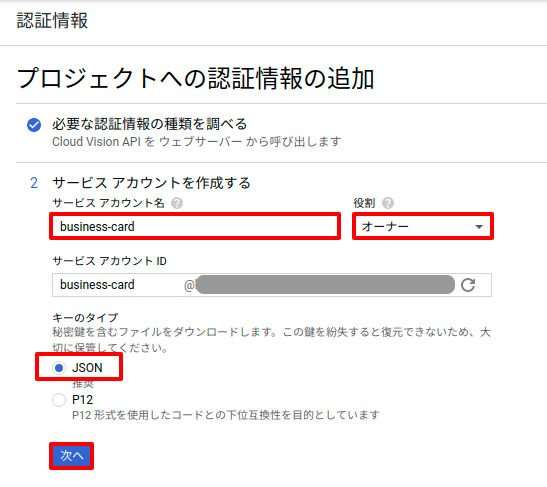
すると、自動でJSONファイルがダウンロードされますので、区別しやすいようにvision_api_key.jsonなどにリネームしてLaravelの/storage/json/フォルダに設置しておいてください。
あとは、Laravel内のどこからでも参照できるように.envに以下のように登録しておきましょう。
GOOGLE_CLOUD_PROJECT=******************* GOOGLE_APPLICATION_CREDENTIALS=/***/***/***/storage/json/vision_api_key.json
VISION_API_PROJECTはvision_api_key.json内の「project_id」に書かれている値です。
Laravelの準備
専用パッケージのインストール
続いてはLaravel側の準備です。
Google Vision APIは専用のパッケージを用意してくれていますので以下のコマンドでインストールしましょう。
composer require google/cloud-vision
※ ちなみに.envでGOOGLE_CLOUD_PROJECTとGOOGLE_APPLICATION_CREDENTIALSが自動的に適用されるのでわざわざAPIキーの設定をする必要はありません。便利です!
ルートを作成する
続いてブラウザからアクセスするURLを設定していきます。routes/web.phpに以下を追加してください。
Route::get('business_card', 'BusinessCardController@index');
Route::post('business_card/extract', 'BusinessCardController@extract');
上がブラウザで実際にアクセスするページで、下がAjax通信でテキストデータを取得するルートになります。
コントローラーを作成する
次に以下のコマンドでコントローラーを作成します。
php artisan make:controller BusinessCardController
app/Http/ControllersBusinessCardController.phpが作成されますので、開いて以下のように変更します。
<?php
namespace App\Http\Controllers;
use Google\Cloud\Vision\V1\ImageAnnotatorClient;
use Illuminate\Http\Request;
use Illuminate\Support\Str;
class BusinessCardController extends Controller
{
public function index() {
return view('business_card.index');
}
public function extract(Request $request) {
$client = new ImageAnnotatorClient();
$image = $client->createImageObject(file_get_contents($request->image));
// テストする場合は直接こちらから画像データを読み込んでください。
// $image = $client->createImageObject(file_get_contents(public_path('/images/business_card_example.png')));
$response = $client->textDetection($image);
if(!is_null($response->getError())) {
return ['result' => false];
}
$annotations = $response->getTextAnnotations();
$description = str_replace('"""', '', $annotations[0]->getDescription());
return [
'result' => true,
'text' => $description
];
}
}
なお、extract()内ではAjaxで送信されてきた画像データ(dataURL)からテキスト抽出し、取得された内容を加工してAjaxへ返すようになっています。($descriptionが抽出データ)
なお、抽出に失敗した場合はresultがfalseになります。
ビューを作成する
では実際にブラウザで目にする部分のビューを作成していきましょう。
<html>
<head>
<link href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<div id="app" class="container">
<br>
<h3>ウェブカメラで名刺を読みとってデータ入力する</h3>
<div class="row">
<div class="col-md-4 form-group">
<label>名前</label>
<input type="text" class="form-control form-control-sm" v-model="params.name">
</div>
<div class="col-md-4 form-group">
<label>会社名</label>
<input type="text" class="form-control form-control-sm" v-model="params.organization">
</div>
<div class="col-md-4 form-group">
<label>住所</label>
<input type="text" class="form-control form-control-sm" v-model="params.address">
</div>
<div class="col-md-4 form-group">
<label>TEL</label>
<input type="text" class="form-control form-control-sm" v-model="params.tel">
</div>
<div class="col-md-4 form-group">
<label>E-Mail</label>
<input type="text" class="form-control form-control-sm" v-model="params.email">
</div>
<div class="col-md-4 form-group">
<label>URL</label>
<input type="text" class="form-control form-control-sm" v-model="params.url">
</div>
</div>
<hr>
<h5>
名刺をウェブカメラに見せて「キャプチャ」ボタンをクリックしてください。<br>
3秒後に画像がキャプチャされます。
</h5>
<div v-show="isModeVideo">
<div class="float-right">
<span class="text-right" v-if="this.timeCount > 0">
@{{ timeCount }} 秒
</span>
<button type="button" class="btn btn-warning" @click="capture">キャプチャ</button>
</div>
<video ref="video" width="640" height="480"></video>
</div>
<div v-show="isModeImage">
<div class="float-right">
キャプチャしました。<br>この画像から情報を読みとりますか?
<br>
<div class="text-right">
<button type="button" class="btn btn-light" @click="cancel">キャンセル</button>
<button type="button" class="btn btn-success" @click="extract">OK</button>
</div>
<div style="white-space:pre;" v-if="extractedText">
<hr>
<span class="badge badge-primary">取得されたテキスト</span>
<div v-text="extractedText" @mouseup="selection"></div>
</div>
</div>
<canvas ref="canvas" width="640" height="480"></canvas>
</div>
<!-- モーダル -->
<div class="modal fade" id="modal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title">自動入力する項目を選択してください</h5>
</div>
<div class="modal-body">
<strong>選択されたテキスト:</strong> <span v-text="selectedText"></span>
<br>
<br>
<h3 class="float-left" v-for="(text,key) in inputs">
<a class="badge badge-primary" href="#" v-text="text" @click.prevent="enterText(key)"></a>
</h3>
</div>
</div>
</div>
</div>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.10/dist/vue.min.js"></script>
<script src="https://code.jquery.com/jquery-3.4.1.min.js"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.19.0/axios.min.js"></script>
<script>
new Vue({
el: '#app',
data: {
params: {
name: '',
organization: '',
address: '',
tel: '',
email: '',
url: ''
},
inputs: {
name: '名前',
organization: '会社名',
address: '住所',
tel: 'TEL',
email: 'E-Mail',
url: 'URL'
},
imageData: null,
mode: 'video',
timeCount: 0,
extractedText: '',
selectedText: ''
},
computed: {
video() {
return this.$refs['video'];
},
canvas() {
return this.$refs['canvas'];
},
context() {
return this.canvas.getContext('2d');
},
isModeVideo() {
return (this.mode === 'video');
},
isModeImage() {
return (this.mode === 'image');
}
},
methods: {
capture() {
this.timeCount = 3;
// 3秒後に画像をキャプチャ
const timer = setInterval(() => {
if(this.timeCount === 1) {
clearInterval(timer);
const video = this.video;
this.context.drawImage(video, 0, 0, video.videoWidth, video.videoHeight);
this.imageData = this.canvas.toDataURL('image/jpeg', 1.0);
this.mode = 'image';
}
this.timeCount -= 1;
}, 1000);
},
cancel() {
this.mode = 'video';
},
extract() {
const url = '/business_card/extract';
const formData = new FormData();
formData.append('image', this.imageData);
axios.post(url, formData)
.then((response) => {
const result = response.data.result;
if(result) {
this.extractedText = response.data.text;
}
});
},
selection() {
this.selectedText = window.getSelection().toString();
if(this.selectedText !== '') {
$('#modal').modal('show');
}
},
enterText(targetKey) {
let newParams = {};
for(let key in this.params) {
if(key === targetKey) {
newParams[key] = this.selectedText;
} else {
newParams[key] = this.params[key];
}
}
this.params = newParams;
$('#modal').modal('hide');
window.getSelection().empty();
}
},
mounted() {
// ウェブカメラへアクセス
navigator.mediaDevices.getUserMedia({ video: true })
.then((stream) => {
this.video.srcObject = stream;
this.video.play();
});
}
});
</script>
</body>
</html>
コードが長いので実際にテストした画像を使って、順を追って説明していきます。
なお、今回読みとりをした名刺は名刺良品さんのこちらのページから.aiファイルをダウンロードして使わせていただきました。ありがとうございました😊✨
ウェブカメラへアクセス
ページが表示されたらすぐ実行されるmounted()の中でウェブカメラへアクセス。ページに動画を表示する。
動画からキャプチャをとる
Google のAPIとはいえ一瞬ではテキスト抽出できませんので、「キャプチャ」ボタンをクリックして3秒後に動画から1コマだけをキャプチャし、その画像を送信するようにします。この処理はcapture()で実装されています。

画像をAjaxで送信する
キャプチャをとり、送信ボタンがクリックされたらAjax通信で/business_card/extractに画像データを送信します。
そして、テキストデータが抽出された場合は、extractedTextの中にデータを格納することで、自動的にその内容がブラウザに表示されます。(Vueのバインディングを使っているため)
これがextract()です。
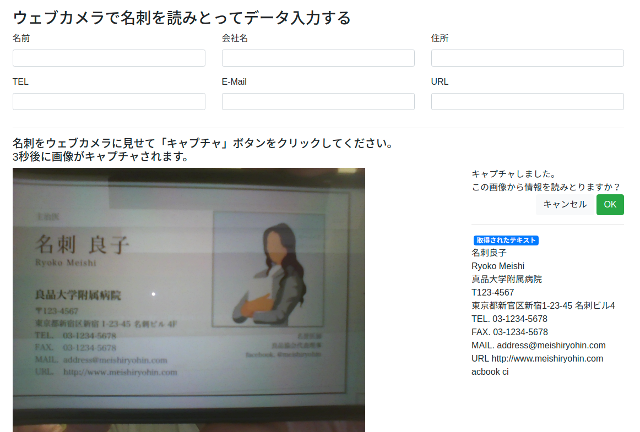
取得したデータをテキストボックスに入れる
当初ここではデータ解析し、名前や住所などを自動で分類して入力することを目指していましたが、名刺のフォーマットは統一ではないため、自動での分類は難しいと判断しました。そのため、今回は表示された文字列を反転させるとモーダル表示され、どの項目に入力するかを選択するような仕様へ変更しました。
※ これは冒頭で紹介した記事が説明するようにNatural Language APIも使ってみましたが、完全ではありませんでしたので仕方なくこのように変更しています。(ただし、もちろん中には成功するものもあります)
以下は文字列が反転(選択)されたときのモーダルと、さらに項目が選択された場合のテキストボックスになります。

これらの処理を行っているのが、selection()とenterText()です。
以上です。
お疲れ様でした!
ソースコード一式をダウンロードする
以下から今回実際に開発したソースコード一式をダウンロードすることができます。
※ ただし、パッケージのインストール、読み取る名刺の準備などはご自身で行っていただく必要があります。
名刺を読みとって会員データを入力おわりに
ということで、今回はウェブカメラで読み取った名刺からテキストを抽出してみました。
ただ、記事中でも書きましたが、当初の想定では名刺を読み取ったら入力まで全自動で完了させる事を想定していたので実際問題は70点ぐらいですね。。(期待していただいてたらスミマセン😭)
とはいえ、手打ちでキーボード入力を何百件としないといけない場合だと今回実装した内容でも多少は業務作業は軽減できるのではないでしょうか。
最後にちょっとだけ言い訳でした。
世の中から腱鞘炎がなくなりますように❗
ではでは〜!

「まだまだ人工知能は人間のレベルには来てないのかも…(願いも込めて)」





