九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、ウェブの世界の技術革新は常に速いスピードで進んでいるのは誰しも実感していることだと思います。(たまに変わりすぎて面食らうぐらいですよね😂)
となると、500以上記事を公開しいるこのブログでもあることが起こってきます。
それが・・・・・・
今は、こっちのがスゲーよ👍
そうです❗
昔記事を公開したときは、(まだあまり知られてなかったので)使っていなかったけど、今は技術が向上して「こっちのがベターだよね」というものが結構あったりするんですね。
そして今回のテーマは・・・・・・
OCR の読み取りを高速化する
です。
※ ちなみに過去記事は以下になります。
📝 【JavaScript】ブラウザだけでカメラ撮影した文字を読み取る(OCR)
WebAssembly(超簡単に言うと、高速道路みたいなもの)を使えばウェブであっても高速処理を行うことができるんですね。
そこで❗
今回は「OCR を WebAssembly で高速化する」という記事をお届けします。
ぜひ何かの参考になりましたら嬉しいです。😊✨
※ ちなみに今回の技術だけでなくZbarのWebAssemblyを使ってバーコードの読み取りも高速化した個人サービス「ネカフェのしおり!」もぜひご覧になってください。
 「最近のマンガだと、
「最近のマンガだと、
『日本三國』
が面白いです!」
開発環境: Laravel 10.x、Vite、Alpine.js
目次
やりたいこと
今回も前回記事に合わせて、以下の内容で実装することにします。
- カメラを起動して写真をとる
- その写真を WebAssembly 版の Tesseract を使ってテキストを読み取る
そして、今回も以下の画像で試してみることにします。
プラスアルファな内容:
なお、今回のWebAssembly版では「テキストの読み取りモデル」が必要になります。しかし、このファイルの容量が少し大きい(約4MB)ので、2回目以降はダウンロードを省略できるようにIndexDBへ保存するようにします。(つまり、キャッシュみたいなものですね)
では今回も楽しんでやってみましょう❗
(パッケージのための)パッケージをインストールする
ちょっと分かりにくいかもしれませんが、次の項目でインストールするパッケージ「tesseract-wasm」の説明書きでは、「手動で必要なファイルをコピーしてね」となっていますが、今後パッケージが更新される可能性もあるため、ビルド時に自動でファイルをコピーするようにしたいですよね。
しかし、ViteにはLaravel-Mixのようなファイル・コピー機能がないので、この「ファイルをコピーするための」パッケージを先にインストールしておきます。
では、以下のコマンドを実行してください。
npm i vite-plugin-static-copy --save-dev
これでコピー用のパッケージがインストールされました。
パッケージをインストールする
では次に、WebAssembly版Tesseractのインストールです。
以下のコマンドを実行してください。
npm install tesseract-wasm
すると、パッケージがnode_modules/tesseract-wasmにインストールされます。
では、まずはtesseract-wasmがLaravelから呼び出せるようにします。
resources/js/bootstrap.js
// 省略
// 👇 追加しました
import { OCRClient } from 'tesseract-wasm';
window.OCRClient = OCRClient;
そして、以下3つのファイルがpulbicフォルダにコピーされるようにします。
- tesseract-core.wasm
- tesseract-core-fallback.wasm
- tesseract-worker.js
Viteの設定ファイルを以下のように変更してください。
vite.config.js
import { defineConfig } from 'vite';
import laravel from 'laravel-vite-plugin';
import { viteStaticCopy } from "vite-plugin-static-copy"; // 👈 ここを追加しました
export default defineConfig({
plugins: [
laravel({
input: [
'resources/css/app.css',
'resources/js/app.js',
],
refresh: true,
}),
viteStaticCopy({ // 👈 ここを追加しました
targets: [
{
src: 'node_modules/tesseract-wasm/dist/tesseract-core.wasm',
dest: 'assets/',
},
{
src: 'node_modules/tesseract-wasm/dist/tesseract-core-fallback.wasm',
dest: 'assets/',
},
{
src: 'node_modules/tesseract-wasm/dist/tesseract-worker.js',
dest: 'assets/',
},
]
})
],
});
なお、少し注意が必要なのがdestの部分です。
なぜassets/を指定しているかと言うと、出力先がpublic/buildフォルダが基準になるためです。
では、この状態で以下のコマンドを実行してビルドしてみましょう。
npm run build
すると、以下のようにコピーされました。

これでパッケージのインストールは完了です。
※ なぜか、ビルドするとにtesseract-core.wasmとtesseract-worker.jsだけはランダム数字付きでファイルが作成されました。でもアクセスしようとするのはランダムなしの方ですし、そもそもtesseract-core-fallback.wasmもないのでなぜ・・・🤔といったところですが、今回は調査していません。
テキスト読み取りモデルを設置する
続いて、Tesseractで利用することになる「テキスト読み取りのためのモデル」ファイルが必要になります。
これらのファイルは「tessdata_fast」というリポジトリで公開されているのですが、今回は英語版をダウンロードして設置することにします。
以下のページに移動し、ダウンロードボタンをクリックしてください。
すると、eng.traineddataというファイルがダウンロードされるので中身を先ほどと同じくpublicフォルダへ移動してください。

※ なお、日本語版は以下のページになります。
これで必要な環境は整いました❗
Tesseract を使ったテキスト読み取り機能を実装する
では、ここからがメインのプログラム部分です。
resources/views/tesseract_wasm.blade.php
<html>
<head>
@vite(['resources/css/app.css', 'resources/js/app.js'])
</head>
<body>
<div x-data="ocr">
<div class="min-h-screen bg-gray-100">
<div class="max-w-7xl mx-auto py-6 px-4 sm:px-6 lg:px-8">
<h1 class="mb-5">Tesseract-wasm: 画像からテキストを読み取る(OCR)サンプル</h1>
<div class="flex items-center">
<input type="file" class="hidden" id="fileInput">
<label class="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded cursor-pointer">
<span>ファイルを選択</span>
<input type="file" class="hidden" @change="onFileChange">
</label>
</div>
</div>
</div>
<template x-if="! isModelLoading">
<div>
<div class="loader-wrapper">
<div class="loader ease-linear rounded-full border-2 border-t-2 border-gray-200 h-6 w-6 animate-spin"></div>
</div>
</div>
</template>
</div>
<script>
const ocr = {
ocr: null,
// Data
tesseractTrainedObjectKey: 'trainedData',
tesseractTrainedDataKey: 'eng.traineddata',
isModelLoading: false,
isOcrInitialized: false,
status: 'none',
// Methods
getTesseractTrainedData() {
return new Promise((resolve, reject) => {
const openRequest = indexedDB.open('tesseractWasmTest', 1);
const objectKey = this.tesseractTrainedObjectKey;
const dataKey = this.tesseractTrainedDataKey;
openRequest.onupgradeneeded = e => {
const db = e.target.result;
if (! db.objectStoreNames.contains(objectKey)) { // 初回のときはオブジェクトを作成
db.createObjectStore(objectKey);
}
};
openRequest.onsuccess = e => {
const db = e.target.result;
const tx = db.transaction(objectKey, 'readwrite');
const store = tx.objectStore(objectKey);
const getRequest = store.get(dataKey);
getRequest.onsuccess = async e => {
const data = e.target.result;
if (data !== undefined) { // すでに IndexedDB に保存済みのとき
console.log('IndexedDB から取得')
resolve(data);
} else {
this.isModelLoading = true;
fetch('/build/assets/eng.traineddata')
.then(response => response.arrayBuffer())
.then(arrayBuffer => {
const data = new Uint8Array(arrayBuffer);
const tx = db.transaction(objectKey, 'readwrite'); // 時間が経つと IndexedDB が close されてしまうので再度取得
const store = tx.objectStore(objectKey);
const putRequest = store.put(data, dataKey);
putRequest.onsuccess = () => {
console.log('IndexedDB に保存');
resolve(data);
};
})
.finally(() => {
this.isModelLoading = false;
})
}
};
};
});
},
scanWithTesseract(imageData) {
return new Promise((resolve, reject) => {
try {
this.ocr.loadImage(imageData)
.then(() => {
this.ocr.getText()
.then(rawText => {
if(rawText.length > 0) {
resolve(rawText);
}
reject();
});
});
} catch (error) {
reject();
}
});
},
// イベント
onFileChange(e) {
if(this.isOcrInitialized === false) {
alert('文字読み取りの準備をしています(初回のみ)。もうしばらくお待ちください。');
return;
}
const files = e.target.files;
if(files.length > 0) {
this.scanStatus = 'scanning';
this.currentCandidateIndex = 0;
const file = files[0];
let reader = new FileReader();
reader.readAsDataURL(file);
reader.onload = e => this.onFileLoad(e);
}
},
onFileLoad(e) {
let img = new Image();
img.onload = async () => {
const width = img.width;
const height = img.height;
let canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
let ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0, width, height);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
console.log('読み取り中..');
this.scanWithTesseract(imageData)
.then(itemCode => {
alert('読み取り成功: '+ itemCode);
})
.catch(() => {
alert('読み取り失敗');
});
};
img.src = e.target.result;
},
init() {
this.ocr = new OCRClient();
try {
this.getTesseractTrainedData()
.then(trainedData => {
this.ocr.loadModel(trainedData)
.then(() => {
this.isOcrInitialized = true;
});
});
} catch (error) {
console.log(error)
}
}
};
</script>
</body>
</html>
この中でやって重要なのが、「プラスアルファな内容」でも書いたIndexDBを使う部分です。
つまり、こういうことです。
# 問題点
Tesseractのテキスト読み取りモデルのファイルサイズが4MB近くある
# 解決策
なので、このモデルがダウンロードされたらIndexDBに格納しておいて、次回以降はそこから高速にファイルを読み込む
あとは、用意したOCRClientのオブジェクトに読み込みたい画像データを突っ込めばテキストを取得してくれます。(本番環境では正規表現などで必要な部分を切り出すといいでしょう👍)
ちなみにisOcrInitializedは「モデルのダウンロードが完了して準備万端かどうか」が分かる変数になっていて、もしまだ準備ができていない場合にファイル選択されるとゴメンナサイするようになってます。
ルートをつくる
では、最後の簡易的なルートを作っておきましょう。
// 省略
Route::get('tesseract_wasm', fn() => view('tesseract_wasm'));
※ 本来はきちんとコントローラーを使って書くべきです。
以上で作業は完了です。
お疲れ様でした。😊✨
テストしてみる
では、実際にテストしてみましょう❗
まずは「https://******/tesseract_wasm」にアクセスすると同時にコンソールを見てみます。
どうなるでしょうか・・・・・・
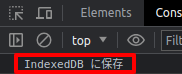
はい❗
IndexDBへモデルの保存が完了しました。
念のため、Applicationタブを開いて保存されているかチェックしておきましょう。

大丈夫ですね👍
では、次のアクセスからIndexDB経由でモデルデータが取得できるかをチェックするために、ページを再読込みします。
うまくいくでしょうか・・・・・・

はい❗
今後は「IndexDB から取得」になりました。
ショートカット成功です😊
では、本題の「画像からテキストを読み取る」部分のテストです。
以下の「ファイルを選択」ボタンをクリックします。
すると、ファイル選択ダイアログが表示されるので以下の画像を選択してみましょう。
結果は・・・・・・

はい❗
完璧にテキストを取得することができました。
すべて成功です😊✨(しかも、1秒もかからないほどの高速でした)
こうすると、少し速度が落ちますがそれでもスマホで3024x4032ピクセルの超解像度な写真で試しても1秒ほどで完了できるようでした。
企業様へのご提案
今回はファイルから選択した画像からテキストを抜き出しましたが、以下のようなことも可能です。
- スマホで撮影した写真からテキストを読み取る
- カメラに写っている画面からリアルタイムにテキストを読み取る
- PDFを画像化して、そこからテキストを読み取る
もしこういった内容をご希望でしたら、いつでもお気軽にお問い合わせからご相談ください。お待ちしております。
おわりに
ということで、今回は「tesseract-wasm」を使ってテキスト抽出をしてみました。
tesseract.jsを使った前回記事では以下のように書きましたが、今回はなんの不便さも感じませんでいた。
ブラウザ版は読み取る内容によってはある程度時間が必要になるため、「お手軽」と「実行速度」のどちらを優先させるか考える必要があると思います。
課題としては、最初のモデルのダウンロード部分ですが毎回時間がかかるよりはマッチ・ベターじゃないでしょうか。
ぜひ皆さんもチャレンジしてみてくださいね。
ではでは〜❗
 「ネカフェはマッサージ機
「ネカフェはマッサージ機
があるので、ついつい
行っちゃいます😊」