

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、前回を除くと最近公開した記事がほぼLaravelの話題がばかりになっていることに気がつきました。Laravelの話題ってホントに尽きないですね😊✨
常々思っているのですが、私の開発環境は現在ドップリLaravel化してしまい、正直なところネイティブなPHPコードの開発は過去1年間でたった一回だけ(しかも古いサイトの移転のお手伝い)だったので、たまにはPHP全般の話題も、といろいろ考えていました。
すると、まっさきに思い浮かんだのが日本語に関連する話題です。
というのもLaravelももちろん多言語にいろいろと対応はしていますが、さすがに単一国家だけで話されている日本語のみに対応するというのはあまりないはずだと考えたからです。
そして、そんな影響で今回お届けするのは、
PHPで「似ているデータ」を見つけ出す方法
です。
しかも、今回は誰でもシンプルに実行できるように難解な公式や機械学習などは全く使いません。
ぜひ皆さんのお役に立てると嬉しいです!

開発環境:PHP 7.2、Ubuntu 18.04、nginx + php-fpm
目次
似ているデータを見つける仕組み
例えば、商品管理システムやブログのように説明文や記事がデータとして存在しているものを想定しています。つまり、少し長い文章が必要になってきます。
というのも、手順としては以下のようになるからです。
- あるデータの説明文から「単語」だけを取り出す
- 取り出した単語から意味のないものなど不要なものを排除する
- 残った単語だけを集計して数が多いものから並べかえる
こうすることで最終的にそのデータに「より関連度が高い」単語だけが取得できるので、これをキーワードとして他のデータを検索すれば、それがそのまま「似ているデータ」になるという訳ですね。
では、ここからは実際に見ていきましょう。
必要なパッケージをインストールする
mecab本体のインストール
日本語から単語だけを抽出するにはmecabと呼ばれるオープンソースの 形態素解析プログラムを利用します。
ということで、まずこのmecab本体をインストールしていきましょう。
以下2つのコマンドを実行してください。
sudo apt install mecab sudo apt install libmecab-dev
インストールが完了したら、mecabが動くかチェックしてみましょう。
以下のコマンドを実行してみてください。
mecab
すると、テキストの入力モードになりますので、例えば「犬も歩けば棒に当たる」と入れて実行してみましょう。
![]()
実行結果はこうなります。
犬 名詞,普通名詞,*,*,犬,いぬ,代表表記:犬/いぬ 漢字読み:訓 カテゴリ:動物
も 助詞,副助詞,*,*,も,も,*
歩けば 動詞,*,子音動詞カ行,基本条件形,歩く,あるけば,代表表記:歩く/あるく
棒 名詞,普通名詞,*,*,棒,ぼう,代表表記:棒/ぼう 漢字読み:音 カテゴリ:人工物-その他;形・模様
に 助詞,格助詞,*,*,に,に,*
当たる 動詞,*,子音動詞ラ行,基本形,当たる,あたる,代表表記:当たる/あたる 自他動詞:他:当てる/あてる 反義:動詞:外れる/はずれる
このように日本語の文章を単語(品詞)ごとに分けてくれるので、この間公開した記事、意外と簡単!Laravel で全文検索をつくる(Laravel Scout + Algolia)でも少し紹介しましたが、全文検索を自前で作るときはとても重宝します。
php-mecabのインストール
続いてmecabがPHPから使えるようにしてみましょう。
【追記:2022.4.14】
PHPのバージョンが新しくなったためか、以下の方法ではmakeするときにエラーが出て実行できませんでした。(実行はPHP 8.0です)もしインストールが出来ない場合は おまけ:exec()でMecabを使う を参照してみてください。
まずは、適当なフォルダに移動して以下のコマンドでコードをローカル環境にコピーします。
git clone https://github.com/rsky/php-mecab.git
次にコピーしたフォルダ内に移動します。
cd php-mecab/mecab
移動したらphpizeコマンドを実行。
phpize
※ もしphpizeコマンドが使えない場合は、以下のコマンドを先に実行してください。(PHPバージョンによって読みかえてください)
sudo apt install php7.2-dev
【追記:2021.09.29】もし php-cli のバージョンが変わらない場合はsudo update-alternatives --set php /usr/bin/php8.0を実行してください。
あとは以下のコマンドを順に実行すればインストールが完了します。
./configure make make test sudo make install
※ 途中Do you want to send this report now?と聞かれたらレポートを送信するかどうかなのでお好みで決定してください。ちなみに、私はn(No)にしました😊
インストールが完了すると以下のような表示が出ます。
Installing shared extensions: /usr/lib/php/********/
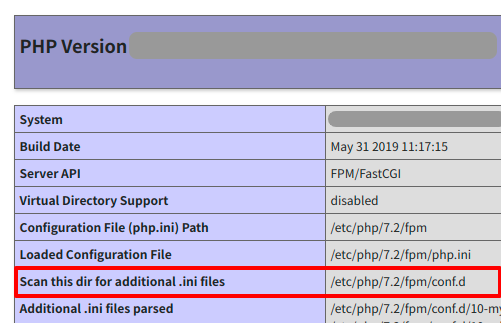
では、php-mecabを有効にするためにmecab.iniファイルを作成しましょう。
作成する場所は、php_info()で表示される「Scan this dir for additional .ini files」と書かれているフォルダがいいでしょう。
mecab.iniの中身は以下のとおりです。
extension=mecab.so
ファイルが作成されたら、以下のコマンドでnginxとphp-fpmを再起動します。(これも環境によって読みかえてください)
sudo systemctl restart nginx sudo systemctl restart php7.2-fpm
そして、再度php_info()を再表示して以下のようにmecabの項目が出ていたら成功です。
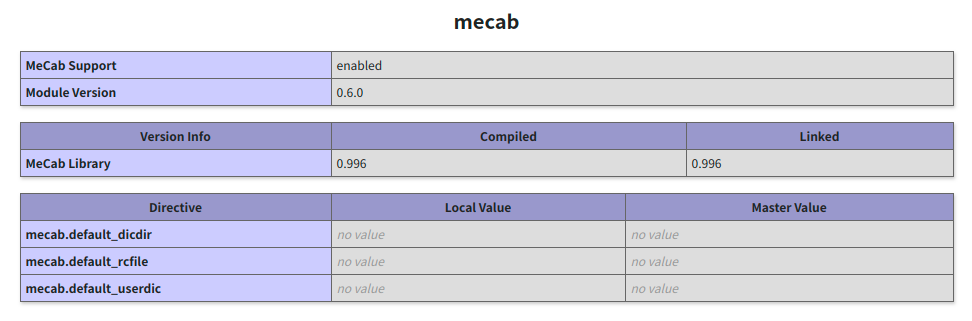
似ているデータを探すコードをつくる
では、準備ができたので実際にPHPのコードを見ていきましょう。
まずは実際のコードです。
$txt = '(ここに説明文などのテキストを入力してください)';
// mecabのインスタンス
$mecab = new \MeCab\Tagger();
$node = $mecab->parseToNode($txt);
$tags = [];
while($node) {
// mecabから各種データを取得
$stat = $node->getStat();
$features = explode(',', $node->getFeature());
$surface = $node->getSurface();
if ($stat === 0 &&
$features[0] === '名詞' &&
$features[1] === '普通名詞') {
$tags[] = $surface; // 条件があえば配列に追加
}
// 次の単語へ移動
$node = $node->getNext();
}
// タグを集計&並べ替えをする
$tag_counts = array_count_values($tags);
$tag_counts = array_filter($tag_counts, function($value){
return ($value >= 3);
});
arsort($tag_counts);
print_r($tag_counts);
やっていることは次のとおりです。
まず、mecabのインスタンスを作成してひとつずつ単語を判別していきます。
ループの中では、まず判別に必要な以下3つのデータを取得します。
- stat ・・・ 0(ゼロ)が単語ブロック
- feature ・・・ 単語の品詞など様々な情報が含まれたテキスト(※1)
- surface ・・・ 単語本体「犬」「棒」など
(※1)例えば「テキスト」の場合は次のようになります。
名詞,普通名詞,*,*,テキスト,てきすと,代表表記:テキスト/てきすと カテゴリ:人工物-その他;抽象物 ドメイン:教育・学習;科学・技術
3つのデータが取得できたらお好みの条件でフィルタをかけます。今回の条件はこうなっています。
- statがゼロのもの(つまり単語ブロックだけで、余分なブロックは無視されます)
- $featuresの一番目と二番目が「名詞」「普通名詞」であること
そして、これらの条件をくぐり抜けることができたものをひとつずつ配列に追加していくことになります。
さらにそれらの単語の中でも優先順位をつけるために、まずarray_count_values()で配列内のデータをカウントします。
実行したものは、以下のようになります(つまり、この中の数字は配列の中に同じ単語が何個あるかを表しています)
Array
(
[個人] => 1
[プログラム] => 1
[起源] => 2
[自身] => 1
[サイト] => 1
[ページ] => 2
[データベース] => 1
そして、array_filter()を使って「何個以上その単語があればタグとして使うか」のフィルターをかけ、さらにarsort()で個数が多い順に配列を並べ替えて最終的に「似ているデータ」を探すためのタグ(キーワード)とします。
ちなみに、wikipediaのPHPのページにある「概要」のテキストを使ってタグ抽出したものが以下になります。
Array
(
[言語] => 7
[ツール] => 4
[関数] => 4
[文字] => 3
)
あとは、DBのフィールドにtagsなどを追加してjsonとしてこれらのタグを保存しておけば、後でいつでも似たデータを取得できるというわけです。
ちなみに – 1
フィルターをかける条件によっては「こと」や「もの」などあまり似たデータを取得するには向かないデータもありますので、次のように漢字のみをOKにしたり、文字が2文字以上のものだけでフィルタをかけるなど工夫するといいと思います。
if ($stat === 0 &&
$features[0] === '名詞' &&
$features[1] === '普通名詞' &&
preg_match('|^[一-龠]+$|u', $surface)) { // 漢字のみ(ただし、全ての漢字をカバーしているわけではないです)
$tags[] = $surface;
}
ちなみに – 2
ホントに「ちなみに」ですが、私が運営している無料プレスリリースサイト「ぷれりり・プレスリリース」でも今回のテクニックを利用して関連するプレスリリースを自動的に表示するようにしています。
ご興味にある方はぜひそちらも参考にしてみてください!
おまけ:exec()でMecab を使う
記事の途中でも書きましたが、PHP 8.0の環境で実行しようとしたところうまくPHPの拡張をインストールすることができませんでした。
そこで、rsky/php-mecab のリポジトリを見ると最終更新されたのは 2015年12月6日 とのことで長い間メンテナンスされていないようでした。(2022.4.14 現在)
そこで、おまけとして拡張をインストールせずにMecabを利用する方法を追記することにしました。
コードは以下です。
$extracting_text = '犬も歩けば棒に当たる';
$tags = [];
exec('echo '. $extracting_text .' | mecab', $output);
if(!empty($output) && is_array($output)) {
$tags = collect($output)
->filter(function($item){
return $item !== 'EOS'; // EOS (End of Sentence) は除外
})
->map(function($item) {
$lines = explode("\t", $item);
$surface = $lines[0];
$features = explode(',', $lines[1]);
return [
'surface' => $surface,
'features' => $features
];
})
->filter(function($item) {
return data_get($item, 'features.0') === '名詞';
})
->pluck('surface')
->toArray();
}
dd($tags);
【追記:2023.9.12】EOSが存在するとエラーになるので filter() 部分を追記しました。
といっても、exec()でコマンドを実行し、返ってきた中身をPHPで加工しているだけです 😄👍
おわりに
短いながらも久しぶりに純粋なPHPコードを書きましたが、配列にフィルタを掛ける場所ではPHPの標準関数より先にLaravelのヘルパー関数の方が思い浮かんでくるので、やっぱりLaravelにドップリはまっちゃってるのを実感してしまいました😂
ただ、今回のコードの中でarray_count_values()などはあまり馴染みのない関数でしたが、とても便利なものがあるのだなとも思いました。(しかもこの関数はPHP4から存在しているようです。全然知らなかったです・・・)
もしかすると、Laravelのヘルパー関数を使わなくても実行できる便利な関数がPHPには用意されているのかもしれません。
そのあたりもできるだけカバーしていきたいですね。
ということで、皆さんも一度mecabで「似ているデータ」を取得してみてはいかがでしょうか。
ではでは〜!






