

九保すこひです(フリーランスのITコンサルタント、エンジニア)
さてさて、以前「Laravelの便利なコレクション・メソッド7選!」を公開した時からいつかやりたいと思っていたのが、
全Laravel Collectionメソッド
の使い方を再チェックすることです。
なぜなら、Laravelはマイナー・バージョンアップでも新しいメソッドを追加するので、定期的にチェックをしておかないとせっかくの便利な機能を見逃してしまうからです。
ということで、過去にあまりにも膨大な量になりそうで敬遠してた「Laravel Collection」の全実例をケース別でまとめてお届けしたいと思います。

開発環境: Laravel 5.6 〜 Laravel 7.x
【追記:2020.3.7】この記事は公開当時Laravel 5.6向けに作成されたものに加筆修正されたものです。そのため、記事の公開より後に追加されたメソッドについては、有効なバージョン情報を載せていますが、もし何も記載が無い場合はLaravel 5.6以降で使えるものとお考えください。
【追記:2020.7.3】takeUntil()、takeWhile()を追加しました。
目次
- 1 データを取得する
- 1.1 get()で指定したキーのデータを取得する
- 1.2 pluck()で指定したキーの配列を取得する
- 1.3 toArray()で中身を配列で取得する
- 1.4 all()で中身を配列で取得する
- 1.5 take()で指定した件数だけデータ取得する
- 1.6 takeUntil()で特定の条件が来るまでデータ取得する
- 1.7 takeWhile()で特定の条件が続く限りデータ取得する
- 1.8 toJson()でJSONデータを取得する
- 1.9 diff()で指定データ「以外」のデータだけ取得する
- 1.10 diffAssoc()でキーの中身が違っているものだけ取得する
- 1.11 diffKeys()でキーが存在しているデータだけ取得する
- 1.12 each()で1行ずつデータを取得する
- 1.13 eachSpread()でデータを変数に格納させながら1行ずつ取得する
- 1.14 only()で指定したキーだけ取得する
- 1.15 except()で指定したキー「以外」を取得する
- 1.16 filter()で条件に合うデータだけを取得する
- 1.17 first()で条件に合う最初のデータだけ取得する
- 1.18 firstWhere()で条件に合うデータだけを取得する
- 1.19 forPage()を使ってページごとのデータを取得する
- 1.20 implode()でデータを結合した文字列を取得する
- 1.21 join()でデータを結合した文字列を取得する(英文法的)
- 1.22 keys()でキーを取得する
- 1.23 values()でインデックス&キーを初期化したデータを取得する
- 1.24 last()で最後のデータを取得する
- 1.25 reduce()でデータをひとつにして取得する
- 1.26 reject()で条件に合わないものを除外してデータ取得する
- 1.27 random()でランダムにデータを取得する
- 1.28 unique()で重複しない値だけを取得する
- 1.29 uniqueStrict()で重複しない値だけを取得する
- 1.30 unwrap()でCollectionの元になったデータを取得する
- 2 集計データを取得する
- 3 データを追加・削除・作成する
- 3.1 push()でデータを最後に追加する
- 3.2 put()でキーと値を追加する
- 3.3 concat()でデータを最後に追加する
- 3.4 combine()でキーと値を結合する
- 3.5 forget()でキーを使ってデータ削除する
- 3.6 pull()で指定キーを削除する
- 3.7 intersect()で存在しない値を削除する
- 3.8 intersectByKeys()で存在しないキーを削除する
- 3.9 merge()で2つのデータを合体させる
- 3.10 mergeRecursive()で2つのデータを重複するキーで合体させる
- 3.11 union()で2つのデータを合併する
- 3.12 prepend()で最初の位置にデータを追加する
- 3.13 shift()で最初のデータを削除する
- 3.14 pop()で最後のデータを削除する
- 3.15 times()で特定の回数分だけデータを作成する
- 3.16 wrap()でCollectionデータを作成する
- 3.17 zip()で多重配列を作成する
- 4 データの構造や値を変更する
- 4.1 chunk()である件数ごとに分割する
- 4.2 split()で指定数にデータを分割する
- 4.3 collapse()でデータを平坦化する
- 4.4 crossJoin()で、あり得る全ての組み合わせを作る
- 4.5 flatMap()で全データを加工する
- 4.6 flatten()で多次元配列を1次元配列にする
- 4.7 flip()でキーと値を入れ替える
- 4.8 groupBy()でキーごとにデータをまとめる
- 4.9 keyBy()でキーごとにデータをまとめる
- 4.10 map()で全てのデータに特定の加工をする
- 4.11 transform()で全てのデータに特定の加工をする
- 4.12 mapInto()で全ての要素を特定クラスのインスタンスにする
- 4.13 mapSpread()で変数に格納しながら新しいデータを作成する
- 4.14 mapToGroups()で1行ずつ取得しながらグループ化する
- 4.15 mapWithKeys()で連想配列をつくる
- 4.16 pad()でデータ数を揃える
- 4.17 partition()で2グループに分ける
- 4.18 pipe()でCollectionをfunction()へ送り返り値を受け取る
- 4.19 skip()で指定の数だけ飛ばしてデータを取得する
- 4.20 slice()でデータを抜き出す
- 4.21 splice()でデータを抜き出す
- 4.22 replace()でデータを入れ替える
- 4.23 replaceRecursive()で階層が深いデータを入れ替える
- 5 データを並べ替える
- 6 データをチェックする
- 7 データの中身を表示する
- 8 条件で分岐させる
- 9 データを絞りこむ
- 9.1 where()でデータを絞り込む
- 9.2 whereStrict()でデータを絞り込む
- 9.3 whereIn()で複数の該当データを絞り込む
- 9.4 whereInStrict()でデータを絞り込む
- 9.5 whereNotIn()で指定データ以外に絞り込む
- 9.6 whereNotInStrict()で指定データ以外に絞り込む
- 9.7 whereInstanceOf()でクラスのインスタンスかどうかで絞り込む
- 9.8 whereBetween()で2つの値の間にあるデータを取得する
- 9.9 whereNotBetween()で2つの値の間は「ない」データを取得する
- 9.10 whereNull()でNullのデータだけ取得する
- 9.11 whereNotNull()でNull「以外」データだけ取得する
- 10 その他
- 11 おわりに
データを取得する
get()で指定したキーのデータを取得する
get()はCollectionの一番基本的なメソッドで、PHPの配列のようにキーを指定してデータを取り出します。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20
]);
echo $collection->get('name'); // 鈴木
また、キーが無い場合は以下のようにインデックス番号を指定することでデータ取得できます。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); echo $collection->get(0); // 鈴木
なお、もし存在しないキーを指定した場合はnullになりますが、第2引数にデフォルト値を指定しておくこともできます。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20
]);
echo $collection->get('todofuken', '東京都'); // 東京都
※デフォルト値はfunction()で設定することもできます。その場合はreturnでデフォルト値を返してください。
pluck()で指定したキーの配列を取得する
例えば、nameの値だけを取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 25],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$names = $collection->pluck('name');
print_r($names->toArray());
実行結果はこうなります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
[3] => 山本
[4] => 藤原
)
また、連想配列として取得することもできます。例えば、idをキーとする連想配列です。
$collection = collect([
['id' => 3, 'name' => '鈴木', 'age' => 20],
['id' => 5, 'name' => '佐藤', 'age' => 23],
['id' => 6, 'name' => '田中', 'age' => 20],
['id' => 9, 'name' => '山本', 'age' => 25],
['id' => 11, 'name' => '藤原', 'age' => 25],
]);
$names = $collection->pluck('name', 'id');
print_r($names->toArray());
実行結果です。
Array
(
[3] => 鈴木
[5] => 佐藤
[6] => 田中
[9] => 山本
[11] => 藤原
)
toArray()で中身を配列で取得する
Collectionの中身を配列にして取得します。
$collection = collect(['鈴木', '佐藤', '田中'])->all(); $array = $collection->toArray(); // 配列
all()で中身を配列で取得する
all()はほぼtoArray()と同じで、Collectionの中身を配列で取得することができます。
$collection = collect(['鈴木', '佐藤', '田中'])->all(); $array = $collection->all(); // 配列
toArray()との違いは、Collectionの中にさらにCollectionが含まれている場合です。
$collection = collect([
collect([1, 2, 3]),
collect([4, 5, 6]),
collect([7, 8, 9])
]);
dd($collection->toArray());
これを実行すると、toArray()の場合は全ての要素をPHPの配列に変換します。
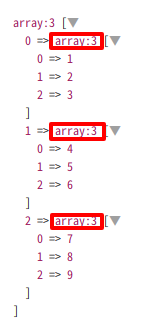
これとは逆に、all()を使った場合、CollectionはCollectionのままで残ることになります。
$collection = collect([
collect([1, 2, 3]),
collect([4, 5, 6]),
collect([7, 8, 9])
]);
dd($collection->all());
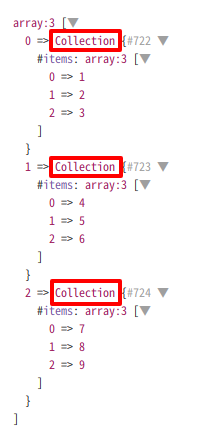
そのため、foreachループなどの中でさらにCollectionのメソッドを使いたい場合はall()を使うほうがいいでしょう。
take()で指定した件数だけデータ取得する
Collectionの中から特定の件数だけを取得します。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $chunk = $collection->take(3); print_r($chunk->toArray());
実行結果は以下のようになります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
)
なお、マイナスの数字を使うと「後ろから●件のデータ」を取得することもできます。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $chunk = $collection->take(-2); print_r($chunk->toArray());
結果はこうなります。
Array
(
[3] => 山本
[4] => 藤原
)
※キーが保持されていることに注意してください。
takeUntil()で特定の条件が来るまでデータ取得する
例えば、データを1件ずつチェックし「三郎」さんが来るまでデータを取得する場合です。
$collection = collect(['太郎', '次郎', '三郎', '四郎', '五郎']);
$users = $collection->takeUntil(function ($item) {
return ($item === '三郎'); // 👈 三郎さんが来るまで続く(ただし、三郎さんは含まない)
});
dd($users->toArray());
結果はこうなります。
array:2 [ 0 => "太郎" 1 => "次郎" ]
Laravel 7.8 以降
takeWhile()で特定の条件が続く限りデータ取得する
$collection = collect(['太郎', '次郎', '三郎', '花子', '四郎']);
$users = $collection->takeWhile(function ($item) {
return (Str::contains($item, '郎')); // 👈 名前に「郎」が入っている限り続く
});
dd($users->toArray());
結果はこうなります。
array:3 [ 0 => "太郎" 1 => "次郎" 2 => "三郎" ]
Laravel 7.8 以降
toJson()でJSONデータを取得する
例えば、Ajax通信などのためにJSON形式のデータを用意したい場合です。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 23
]);
echo $collection->toJson();
実行結果はこうなります。
{"id":1,"name":"\u9234\u6728","age":23}
ちなみにLaravelのCollectionはtoJson()を使わなくとも、echo で表示してやれば自動的にJSON形式になってくれます。
echo collect([
'id' => 1,
'name' => '鈴木',
'age' => 23
]); // (上の例と同じになります)
diff()で指定データ「以外」のデータだけ取得する
Collectionの中から指定したもの「以外」のデータを取得します。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $diff = $collection->diff(['鈴木', '佐藤', '田中']); print_r($diff->toArray());
この場合、実行結果は以下のようになります。
Array
(
[3] => 山本
[4] => 藤原
)
※キーが保持されていることに注意してください。
diffAssoc()でキーの中身が違っているものだけ取得する
「キーがお互い存在していて、なおかつその値が違っているデータ」だけを取得します。
$collection = collect([
'name' => '鈴木',
'age' => 20,
'todofuken' => '東京都'
]);
$diff = $collection->diffAssoc([
'name' => '佐藤',
'age' => 15,
'todofuken' => '大阪府',
'height' => '170cm'
]);
print_r($diff->toArray());
これを実行するとこうなります。
Array
(
[name] => 鈴木
[age] => 20
)
diffKeys()でキーが存在しているデータだけ取得する
元データだけに存在するキーだけを取得するメソッドです。
$collection = collect([
'name' => '鈴木',
'age' => 20,
'todofuken' => '東京都',
'height' => '170cm'
]);
$diff = $collection->diffKeys([
'name' => '佐藤',
'todofuken' => '大阪府'
]);
print_r($diff->toArray());
この場合、以下のようにdiffKeys()に含まれていないageとheightだけが取得されることになります。
Array
(
[age] => 20
[height] => 170cm
)
each()で1行ずつデータを取得する
Collectionの中身を1行ずつ取り出すことができます。(つまりループさせます)
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
$collection->each(function ($item, $key) {
echo $key .': '. $item; // 順にキー(インデックス)と値が取得できます
});
もし途中で終了したい場合はreturn false;を実行します。
$collection->each(function ($item, $key) {
echo $key .': '. $item; // 順に名前が取得できます
return false;
});
eachSpread()でデータを変数に格納させながら1行ずつ取得する
each()のように1行ずつデータを取得しますが少しそのやり方が少し違っています。
実際の例を見てみましょう。
$collection = collect([
[1, '鈴木', 20],
[2, '佐藤', 22],
[3, '田中', 30]
]);
$collection->eachSpread(function($id, $name, $age){
// 何かの処理
});
function()内の引数がそれぞれの配列の位置(インデックス)に対応しています。なお、キーがあるCollectionではエラーになりますので注意してください。
only()で指定したキーだけ取得する
例えば、idとnameだけを取得したい場合です。
$collection = collect(['id' => 1, 'name' => '鈴木', 'age' => 20, 'height' => '170cm']); $filtered = $collection->only(['id', 'name']); print_r($filtered->toArray());
これを実行すると以下のようになります。
Array
(
[id] => 1
[name] => 鈴木
)
except()で指定したキー「以外」を取得する
only()とは逆に、例えばidとname「以外」を取得したい場合です。
$collection = collect(['id' => 1, 'name' => '鈴木', 'age' => 20, 'height' => '170cm']); $filtered = $collection->except(['id', 'name']); print_r($filtered->toArray());
実行結果はこうなります。
Array
(
[age] => 20
[height] => 170cm
)
filter()で条件に合うデータだけを取得する
例えば、「テストで80点以上取った人」だけを取得する場合です。
$collection = collect([70, 100, 35, 82]);
$filtered = $collection->filter(function($value, $key){
return ($value >= 80);
});
print_r($filtered->toArray());
これを実行するとこうなります。(キーが保持されていることに注意してください。)
Array
(
[1] => 100
[3] => 82
)
ちなみに、function(){ ... }が指定されていない場合は、条件式で false になるものが全て削除されます。
$collection = collect(['鈴木', '佐藤', '田中', null, false, '', 0, []]); $filtered = $collection->filter(); print_r($filtered->toArray());
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
)
first()で条件に合う最初のデータだけ取得する
例えば、「テストで最初に80点以上だった点数」を取得する場合です。
$collection = collect([70, 50, 82, 35]);
echo $collection->first(function ($value, $key) {
return ($value >= 80);
}); // 82
もちろん、function(){ ... }を指定しない場合は一番最初のデータが取得されます。
$collection = collect([70, 50, 82, 35]); echo $collection->first(); // 70
firstWhere()で条件に合うデータだけを取得する
where()のように「条件に合う最初のデータ」を取得するメソッドです。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 22],
['id' => 3, 'name' => '田中', 'age' => 30]
]);
$array = $collection->firstWhere('name', '鈴木');
print_r($array);
もちろん以下のように比較演算子を使うこともできます。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 18],
['id' => 2, 'name' => '佐藤', 'age' => 22],
['id' => 3, 'name' => '田中', 'age' => 30]
]);
$array = $collection->firstWhere('age', '>', 20);
ちなみに、条件に合うものがない場合は結果は、nullになります。
forPage()を使ってページごとのデータを取得する
「現在のページ番号」と「件数」を指定してデータ取得するメソッドです。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $chunk = $collection->forPage(0, 3); print_r($chunk->toArray());
この例で言うと、データの0件目(=鈴木)から3件分のデータを取得するという意味になり、結果は以下のようになります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
)
implode()でデータを結合した文字列を取得する
値を結合し、文字列としてデータ取得するメソッドです。例えば、名前を「&」で繋いで結合する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 30]
]);
echo $collection->implode('name', ' & '); // 鈴木 & 佐藤 & 田中
もし、1次元配列の場合はキーは必要なく、以下のように結合文字だけを指定するだけでOKです。
$collection = collect(['鈴木', '佐藤', '田中']);
echo $collection->implode(' & '); // 鈴木 & 佐藤 & 田中
join()でデータを結合した文字列を取得する(英文法的)
ほぼ implode() と同じで値を結合するメソッドですが、こちらはより英文法を考慮しているので、通常はimplode()を使うことをおすすめします。
例を見てみましょう。
echo collect(['あ', 'い', 'う', 'え', 'お'])->join('、');
この場合、「あ、い、う、え、お」が出力されることになりますのでimplode()と全く同じです。
ただ、第2引数を使った場合に違いが英文法への対応が出ます。
echo collect(['A', 'B', 'C', 'D', 'E'])->join(',', ' and ');
この場合、出力されるのは「A,B,C,D and E」と最後のつなぎ部分だけandが適用されることになります。
つまり、日本語ではあまり使いどころはないかもしれません。
Laravel 5.8.4 以降
keys()でキーを取得する
例えば、コレクションから id、 name、ageという「キー」を取得したい場合です。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20
]);
$keys = $collection->keys();
print_r($keys->toArray()); // ['id', 'name', 'age']
ちなみに、以下のように多重配列の場合でも1次元のキーが全て取得できます。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20,
'hobbies' => [
'ピアノ',
'読書'
]
]);
$keys = $collection->keys();
(実行結果)
Array
(
[0] => id
[1] => name
[2] => age
[3] => hobbies
)
values()でインデックス&キーを初期化したデータを取得する
インデックス&キーを初期化したデータを取得します。
$collection = collect([
2 => '鈴木',
5 => '佐藤',
10 => '田中',
4 => '山本',
'name' => '藤原'
]);
$new_collection = $collection->values();
print_r($new_collection->toArray());
これを実行するとこうなります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
[3] => 山本
[4] => 藤原
)
Collectionにはキーを保持するメソッドも多くありますが、そのキーをならしたい場合は以下のように「->」でつなげてvalues()を使うといいでしょう。
$collection->slice(2, 2)->values();
last()で最後のデータを取得する
一番最後のデータを取得する場合です。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); echo $collection->last(); // 藤原
また、function(){ ... }を使えば「条件に合う最後のデータ」を取得することもできます。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 19],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 17],
['id' => 4, 'name' => '山本', 'age' => 25],
['id' => 5, 'name' => '藤原', 'age' => 19],
]);
$array = $collection->last(function($item, $key){
return ($item['age'] >= 20); // 20歳以上
});
print_r($array);
この例で取得できるデータは、山本さんのデータになります。
Array
(
[id] => 4
[name] => 山本
[age] => 25
)
reduce()でデータをひとつにして取得する
例えば、値を使って1つの文字列をつくりたい場合です。
$collection = collect(['鈴木', '佐藤', '田中']);
echo $collection->reduce(function($carry, $item){
return $item .'。'. $carry;
}); // 田中。佐藤。鈴木。
上の例で、$carryは文字列が結合してどんどん長くなっていきます。時間順に中身を見てみましょう。
- 鈴木。
- 佐藤。鈴木。
- 田中。佐藤。鈴木。
もし初期のデータを決めておきたい場合は第2引数へ入れましょう。
$collection = collect(['鈴木', '佐藤', '田中']);
echo $collection->reduce(function($carry, $item){
return $item .'。'. $carry;
}, 'です'); // 田中。佐藤。鈴木。です
reject()で条件に合わないものを除外してデータ取得する
例えば、「20歳未満のデータを除外する」場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 15],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 19],
['id' => 5, 'name' => '藤原', 'age' => 16],
]);
$filtered = $collection->reject(function($values, $key){
return ($values['age'] < 20); // 20歳未満は「除外」
});
print_r($filtered->toArray());
これを実行するとこうなります。
Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 23
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 20
)
)
※注意が必要なのは、条件式がtrueになるものは除外されるという点です。英単語に馴染みがないと直感的にはfalseにしてしまいそうになりますが、逆になっています。
random()でランダムにデータを取得する
例えば、ランダムに名前を取得する場合です。
$collection = collect(['鈴木', '佐藤', '田中', '佐藤', '田中']); echo $collection->random(); // 例: 鈴木(ランダムに変わる)
また、データを複数取得する場合は引数に件数を入れます。
$collection = collect(['鈴木', '佐藤', '田中', '佐藤', '田中']); $names = $collection->random(3); print_r($names->toArray());
unique()で重複しない値だけを取得する
例えば、重複しない名前を取得する場合です。
$collection = collect(['鈴木', '佐藤', '田中', '佐藤', '田中']); $unique = $collection->unique(); print_r($unique->toArray());
これを実行するとこうなります。元データの中には、「佐藤」「田中」が重複していましたが、処理後はひとつだけになっています。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
)
また、多重配列の場合はキーを指定してやることでユニークなデータを取得することもできます。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 16],
['id' => 2, 'name' => '佐藤', 'age' => 30],
['id' => 3, 'name' => '田中', 'age' => 27],
['id' => 4, 'name' => '佐藤', 'age' => 35],
['id' => 5, 'name' => '田中', 'age' => 23],
]);
$unique = $collection->unique('name');
print_r($unique->toArray());
実行結果はこうなります。
Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 16
)
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 30
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 27
)
)
さらに、function(){ ... }を使えばより複雑なユニークデータを作成することもできます。例えば、以下のように「名前」+「年齢」で処理する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 16],
['id' => 2, 'name' => '佐藤', 'age' => 30],
['id' => 3, 'name' => '田中', 'age' => 27],
['id' => 4, 'name' => '佐藤', 'age' => 35],
['id' => 5, 'name' => '田中', 'age' => 27],
]);
$unique = $collection->unique(function($item){
return $item['name'] .'-'. $item['age']; // 例:鈴木-16
});
print_r($unique->toArray());
実行結果はこうなります。名前と年齢がともに同じ2つの「田中」さんは重複しているとみなされ1つのデータになっています。
Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 16
)
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 30
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 27
)
[3] => Array
(
[id] => 4
[name] => 佐藤
[age] => 35
)
)
uniqueStrict()で重複しない値だけを取得する
unique()とほぼ同じですが、重複しているかどうかをチェックする際により厳しくチェックされます。
つまり、以下のような変数の型までチェックする方法になります。
if($a === $b) {}
※使い方は同じなので前項目のunique()をご覧ください。
unwrap()でCollectionの元になったデータを取得する
可能であれば元になったデータを取得するメソッドです。
$collection = Collection::unwrap(collect(['鈴木', '佐藤', '田中', '山本'])); print_r($collection);
集計データを取得する
count()でデータ数を取得する
どれだけの要素がコレクションに入っているかを取得します。
$collection = collect(['鈴木', '佐藤', '田中']); echo $collection->count(); // 3
countBy()で個別のデータ件数を取得する
例えば、同じ年齢が何人含まれているかを集計する場合です。
$ages = [23, 27, 25, 20, 27, 27, 20]; // 年齢 $counted = collect($ages)->countBy(); print_r($counted->toArray());
結果はこうなります。
Array
(
[23] => 1
[27] => 3
[25] => 1
[20] => 2
)
また、countBy()はコールバック関数を使うことで加工した後のデータで集計することもできます。
例えば、「年齢が25才以上かそうでないか」で分けて集計してみましょう。
$ages = [23, 27, 25, 20, 27, 27, 20]; // 年齢
$counted = collect($ages)->countBy(function($age) {
if($age >= 25) {
return 'yes'; // 25才以上の場合
} else {
return 'no';// 25才未満の場合
}
});
print_r($counted->toArray());
結果はこうなります。
Array
(
[no] => 3
[yes] => 4
)
Laravel 5.8.3 以降
avg(), average()でデータの平均値を取得する
データの平均値を取得することができます。
$collection = collect([1, 2, 3, 4, 5]); echo $collection->avg(); // 3
また、avg()はキーが入ったデータにも対応しています。その場合は引数に平均値を取得したいキーを入れましょう。
$collection = collect([
['name' => '鈴木', 'age' => 20],
['name' => '佐藤', 'age' => 22],
['name' => '田中', 'age' => 30]
]);
echo $collection->avg('age'); // 24
※avg()とaverage()は同じものです。
max()で最大値を取得する
データの中から最大値を取得します。
$collection = collect([1, 2, 3, 4, 5]); echo $collection->max(); // 5
また、キーを指定することもできます。
$collection = collect([
['name' => '鈴木', 'age' => 20],
['name' => '佐藤', 'age' => 22],
['name' => '田中', 'age' => 30]
]);
echo $collection->max('age'); // 30
min()で最小値を取得する
データの中から最小値を取得します。
$collection = collect([1, 2, 3, 4, 5]); echo $collection->min(); // 1
また、max()と同じくキーを指定することもできます。
$collection = collect([
['name' => '鈴木', 'age' => 20],
['name' => '佐藤', 'age' => 22],
['name' => '田中', 'age' => 30]
]);
echo $collection->min('age'); // 20
sum()で合計値を取得する
全データの合計を取得します。
$collection = collect([1, 2, 3, 4, 5]); echo $collection->sum(); // 15
また、多重配列の場合はキーを指定して合計値を取得することもできます。以下は点数の合計値を取得する例です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'score' => 83],
['id' => 2, 'name' => '佐藤', 'score' => 67],
['id' => 3, 'name' => '田中', 'score' => 98],
['id' => 4, 'name' => '山本', 'score' => 32],
['id' => 5, 'name' => '藤原', 'score' => 45],
]);
echo $collection->sum('score'); // 325
さらに、function(){ ... }を使うとより複雑な合計値を取得することもできます。例えば、点数の2乗を合計した値を取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'score' => 83],
['id' => 2, 'name' => '佐藤', 'score' => 67],
['id' => 3, 'name' => '田中', 'score' => 98],
['id' => 4, 'name' => '山本', 'score' => 32],
['id' => 5, 'name' => '藤原', 'score' => 45],
]);
echo $collection->sum(function($item){
return pow($item['score'], 2);
}); // 24031
median()で中央値を取得する
データの中央値を取得します。
$collection = collect([1, 3, 5]); echo $collection->median(); // 3
なお、多重配列の場合はキーを指定することで以下のような使い方もできます。
$collection = collect([
['age' => 17],
['age' => 23],
['age' => 30],
['age' => 19],
['age' => 5],
]);
echo $collection->median('age'); // 19
mode()で最頻値(モード)を取得する
データから最頻値を取得します。
$collection = collect([1, 1, 2, 4]); print_r($collection->mode());
また、多重配列の場合はキーを指定することもできます。
$collection = collect([
['age' => 10],
['age' => 10],
['age' => 20],
['age' => 40]
]);
print_r($collection->mode('age'));
nth()でn番目のデータを取得する
ある倍数ごとのインデックスからデータ取得します。(つまりインデックス0番目も入ります)
$collection = collect([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]); $new_collection = $collection->nth(3); print_r($new_collection->toArray());
これを実行したものが以下になります。
Array
(
[0] => 1
[1] => 4
[2] => 7
[3] => 10
)
search()で指定した値のキーを取得する
例えば、たくさんある名前の中から「田中」さんが何番目かを知りたいとき場合です。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
echo $collection->search('田中'); // 2
この場合はインデックス、つまりゼロから始まる数字になることに注意してください。
また値が見つからない場合はfalseが返されます。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
$collection->search('加藤'); // false
さらに、「データの型」まで考慮した比較をする場合は、以下のように第2引数をtrueにします。
$collection = collect([1, 2, 3, 4, 5]);
echo $collection->search('1', true); // 文字列なので見つからない
つまり、以下のようなif文を思い浮かべるといいでしょう。
if($a === $b) {}
なお、search()にはfunction(){ ... }を使うこともできます。例えば20歳以上のデータを探す場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 15],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 19],
['id' => 5, 'name' => '藤原', 'age' => 16],
]);
echo $collection->search(function($item, $key){
return ($item['age'] >= 20); // 20才以上
}); // 1(2番めのデータ)
duplicates()で重複する値を取得する
例えば、あるコレクションの中の「どの位置で重複したデータが存在しているか」を集計する場合です。
$names = [
'山田太郎', // 0
'佐藤次郎', // 1
'佐藤次郎', // 2
'山田太郎', // 3
'田中三郎', // 4
'山田太郎', // 5
];
$collection = collect($names)->duplicates();
print_r($collection->toArray());
この場合、重複が見つかる場所は以下のとおりです。
- 山田太郎: インデックス番号「3」「5」
- 佐藤次郎: インデックス番号「2」
- 田中三郎: (重複なし)
つまり、結果はこうなります。
Array
(
[2] => 佐藤次郎
[3] => 山田太郎
[5] => 山田太郎
)
また、duplicates()はオブジェクトにも対応していて、以下の場合は引数にターゲットにしたいキーをセットします。
$users = [
['id' => 1, 'name' => '山田太郎', 'email' => 'taro@example.com'], // 0
['id' => 2, 'name' => '佐藤次郎', 'email' => 'jiro@example.com'], // 1
['id' => 2, 'name' => '佐藤次郎', 'email' => 'jiro@example.com'], // 2
['id' => 1, 'name' => '山田太郎', 'email' => 'taro@example.com'], // 3
['id' => 3, 'name' => '田中三郎', 'email' => 'saburo@example.com'], // 4
['id' => 1, 'name' => '山田太郎', 'email' => 'taro@example.com'], // 5
];
$collection = collect($users)->duplicates('name');
print_r($collection->toArray());
結果は、先ほどと同じです。
Laravel 5.8.12 以降
duplicatesStrict()でより厳格に重複する値を取得する
ほぼduplicates()と同じですが、集計する際にデータの「型」も同じでないと集計されません。
例えば以下の例をみてください。
$numbers = [1, 2, '1', 3, 2]; $collection = collect($numbers)->duplicatesStrict();
この場合、1は2つ存在していますが、一方は「数値」でもう一つは「文字列」です。そのため、1は重複したとはみなされません。
結果として、重複するのは2のみなので、以下のようになります。
Array
(
[4] => 2
)
その他の使い方はduplicates()をご覧ください。
Laravel 5.8.12 以降
データを追加・削除・作成する
push()でデータを最後に追加する
最後にデータを追加します。
$collection = collect(['赤', '青']);
$collection->push('黄色');
print_r($collection->toArray());
これを実行すると以下のようになります。
Array
(
[0] => 赤
[1] => 青
[2] => 黄色
)
ちなみに、引数に配列を指定するとそのまま配列構造が残るので注意してください。
$collection = collect(['赤']); $collection->push(['青', '黄色']); print_r($collection->toArray());
Array
(
[0] => 赤
[1] => Array
(
[0] => 青
[1] => 黄色
)
)
そのため、一気に複数のデータを同じ次元にデータ追加したい場合は concat() を使いましょう。
put()でキーと値を追加する
キーと値を追加します。
$collection = collect(['id' => 1, 'name' => '鈴木']);
$collection->put('age', 20);
print_r($collection->toArray());
実行結果はこうなります。
Array
(
[id] => 1
[name] => 鈴木
[age] => 20
)
なお、以下のようにすることで追加することもできます。
$collection = collect(['id' => 1, 'name' => '鈴木']); $collection['age'] = 20; // これでも追加できる
concat()でデータを最後に追加する
一番最後に新しいデータを追加することができます。(ただし、1次元配列として追加される)
$collection = collect(['赤']); $concatenated = $collection->concat(['青'])->concat(['黄色', '白']); print_r($concatenated->toArray());
これを実行すると以下のようになります。
Array
(
[0] => 赤
[1] => 青
[2] => 黄色
[3] => 白
)
※push()でも一番最後にデータを追加することができますが、引数が配列の場合、そのまま配列が追加されます。(つまり多次元配列になります)
combine()でキーと値を結合する
例えば、名前(name)と都道府県(todofuken)のデータを作成する場合を見てみましょう。
$collection = collect(['name', 'todofuken']); $combined = $collection->combine(['鈴木太郎', '東京都']); print_r($combined->toArray());
この実行結果はこうなります。
Array
(
[name] => 鈴木太郎
[todofuken] => 東京都
)
※キーと値の件数が違っている場合はエラーが発生するので気をつけてください。
forget()でキーを使ってデータ削除する
キーを指定してデータを削除します。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 25
]);
$collection->forget('name');
print_r($collection->toArray());
これを実行すると以下のようになります。
Array
(
[id] => 1
[age] => 25
)
また、削除したいキーは配列を使って一気に指定することもできます。
$collection->forget(['name', 'age']);
pull()で指定キーを削除する
キーを指定してデータを削除します。
$collection = collect(['id' => 1, 'name' => '鈴木', 'age' => 20]);
$collection->pull('name');
print_r($collection->toArray());
これを実行すると以下のようになります。
Array
(
[id] => 1
[age] => 20
)
ちなみにforget()と同じように見えますが、pull()は削除した値を返します。
$collection = collect(['id' => 1, 'name' => '鈴木', 'age' => 20]);
echo $collection->pull('name'); // 鈴木
intersect()で存在しない値を削除する
指定した値にないものを削除します。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $intersect = $collection->intersect(['鈴木', '田中', '山本']); print_r($intersect->toArray());
実行結果はこうなります。(キーが保持されていることに注意してください)
Array
(
[0] => 鈴木
[2] => 田中
[3] => 山本
)
intersectByKeys()で存在しないキーを削除する
intersect()の場合は、値を使って存在しないものを削除しましたがintersectByKeys()は、配列を使って指定します。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20
]);
$intersect = $collection->intersectByKeys(['name' => '佐藤']);
print_r($intersect->toArray());
上の例では、指定したキー「name」以外のデータが全て削除され結果は以下のようになります。
Array
(
[name] => 鈴木
)
merge()で2つのデータを合体させる
例えば、id、nameだけデータとageだけのデータを合体する場合です。
$collection = collect(['id' => 1, 'name' => '鈴木']); $merged = $collection->merge(['age' => 20]); print_r($merged->toArray());
実行結果はこうなります。
Array
(
[id] => 1
[name] => 鈴木
[age] => 20
)
※ちなみにキーが重複している場合は新しいデータで上書きされます。
また、もちろんキーがついていない配列でもmerge()は使えます。
$collection = collect(['鈴木', '佐藤', '田中']); $merged = $collection->merge(['山本', '藤原']);
結果はこうなります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
[3] => 山本
[4] => 藤原
)
Laravel 5.8.28 以降
mergeRecursive()で2つのデータを重複するキーで合体させる
merge()と似ていますが、こちらは「重複キーを使って合体」させることになります。
例を見てみましょう。
$user_1 = ['id' => 1, 'name' => '山田太郎']; $user_2 = ['id' => 2, 'name' => '佐藤次郎', 'age' => 20]; $merged = collect($user_1)->mergeRecursive($user_2); print_r($merged->toArray());
この場合、キーのうちidとnameは重複するので配列として合体されます。ただし、ageは重複しないので配列にはなりません。
結果はこうなります。
Array
(
[id] => Array
(
[0] => 1
[1] => 2
)
[name] => Array
(
[0] => 山田太郎
[1] => 佐藤次郎
)
[age] => 20
)
Laravel 5.8.28 以降
union()で2つのデータを合併する
merge()と似ていますが、違いは「重複するデータの取り扱い方」です。union()は、すでにキーが存在している場合、元のデータが優先されます。
$collection = collect(['id' => 1, 'name' => '鈴木']); $union = $collection->union(['age' => 23, 'id' => 2]); print_r($union->toArray());
これを実行するとこうなります。idが重複していますが、元の1が優先されて残っています。
Array
(
[id] => 1
[name] => 鈴木
[age] => 23
)
prepend()で最初の位置にデータを追加する
先頭に新しいデータを追加します。
$collection = collect(['鈴木', '佐藤', '田中', '佐藤', '田中']);
$collection->prepend('高橋');
print_r($collection->toArray());
これを実行するとこうなります。(※インデックスの値は保持されません。)
Array
(
[0] => 高橋
[1] => 鈴木
[2] => 佐藤
[3] => 田中
[4] => 佐藤
[5] => 田中
)
また、連想配列に追加する場合は第2引数にキーを指定します。
$collection = collect(['name' => '鈴木', 'age' => 20]); $collection->prepend(1, 'id');
shift()で最初のデータを削除する
一番最初のデータを削除します。
$collection = collect(['鈴木', '佐藤', '田中', '佐藤', '田中']); $collection->shift(); print_r($collection->toArray());
実行結果は削除された「鈴木」以外の4人になります。
Array
(
[0] => 佐藤
[1] => 田中
[2] => 佐藤
[3] => 田中
)
また、shift()の返り値は削除されたデータになります。
echo $collection->shift(); // 鈴木
pop()で最後のデータを削除する
一番最後のデータを削除する場合です。
$collection = collect(['鈴木', '佐藤', '田中', '佐藤', '田中']); $collection->pop(); print_r($collection->toArray());
実行結果は削除された「田中」以外の4人になります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
[3] => 佐藤
)
また、pop()の返り値は削除されたデータになります。
echo $collection->pop(); // 田中
times()で特定の回数分だけデータを作成する
例えば、「その1」〜「その10」というデータを作る例を見てみましょう。
$collection = Collection::times(10, function($number) {
return 'その'. $number;
});
print_r($collection->toArray());
第1引数がデータの件数で、第2引数はそのデータを作る関数です。Seederでテストデータを作るのに重宝するでしょう。
wrap()でCollectionデータを作成する
可能であればCollectionデータを作成します。
$collection = Collection::wrap(['鈴木', '佐藤', '田中']);
zip()で多重配列を作成する
元データにそれぞれ新しい値を追加し、多重配列を作成します。例えば、生徒データとテスト結果を結びつける場合です。
$collection = collect(['鈴木', '佐藤', '田中']); $zipped = $collection->zip([80, 73, 23]); print_r($zipped->toArray());
これを実行するとこうなります。
Array
(
[0] => Array
(
[0] => 鈴木
[1] => 80
)
[1] => Array
(
[0] => 佐藤
[1] => 73
)
[2] => Array
(
[0] => 田中
[1] => 23
)
)
データの構造や値を変更する
chunk()である件数ごとに分割する
たくさんあるデータを特定の件数ごとに分割します。
実際の例を見てみましょう。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $chunks = $collection->chunk(2); print_r($chunks->toArray());
この場合、名前データを2件ずつに分割します。結果は以下のようになります。なお、配列の中身のキーが保持されて0〜4になっていることに注意してください。
Array
(
[0] => Array
(
[0] => 鈴木
[1] => 佐藤
)
[1] => Array
(
[2] => 田中
[3] => 山本
)
[2] => Array
(
[4] => 藤原
)
)
split()で指定数にデータを分割する
chunk()の場合はデータ件数を指定して分割をしましたが、split()では「何分割したいか」で指定します。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $groups = $collection->split(3); print_r($groups->toArray());
この例ではデータを3分割にしています。
実行結果はこうなります。
Array
(
[0] => Array
(
[0] => 鈴木
[1] => 佐藤
)
[1] => Array
(
[2] => 田中
[3] => 山本
)
[2] => Array
(
[4] => 藤原
)
)
collapse()でデータを平坦化する
多重配列となったデータを平坦化します。
$collection = collect([
['鈴木', '佐藤'],
['田中', '山本'],
['藤原']
]);
$collapsed = $collection->collapse();
print_r($collapsed->toArray());
これを実行したものが以下になります。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
[3] => 山本
[4] => 藤原
)
crossJoin()で、あり得る全ての組み合わせを作る
例えば、料理と飲み物の組み合わせ全てを取得する場合です。
$collection = collect(['ラーメン', 'カレーライス', 'お好み焼き']); $new_collection = $collection->crossJoin(['お茶', 'コーラ', '水']); print_r($new_collection->toArray());
結果は、以下のようになります。
Array
(
[0] => Array
(
[0] => ラーメン
[1] => お茶
)
[1] => Array
(
[0] => ラーメン
[1] => コーラ
)
[2] => Array
(
[0] => ラーメン
[1] => 水
)
[3] => Array
(
[0] => カレーライス
[1] => お茶
)
[4] => Array
(
[0] => カレーライス
[1] => コーラ
)
[5] => Array
(
[0] => カレーライス
[1] => 水
)
[6] => Array
(
[0] => お好み焼き
[1] => お茶
)
[7] => Array
(
[0] => お好み焼き
[1] => コーラ
)
[8] => Array
(
[0] => お好み焼き
[1] => 水
)
)
さらに、引数を多重配列にすることで、より多くの組み合わせを取得することもできます。以下は、ハンバーガーのセットを注文するときの全組み合わせの例です。
$collection = collect(['チーズバーガー', 'てりやきバーガー', 'ビッグマック']);
$new_collection = $collection->crossJoin(
['フライドポテト', 'チキンナゲット'],
['コーヒー', 'コーラ', 'お茶']
);
print_r($new_collection->toArray());
これを実行すると以下のような組み合わせが取得できます。
Array
(
[0] => Array
(
[0] => チーズバーガー
[1] => フライドポテト
[2] => コーヒー
)
[1] => Array
(
[0] => チーズバーガー
[1] => フライドポテト
[2] => コーラ
)
[2] => Array
(
[0] => チーズバーガー
[1] => フライドポテト
[2] => お茶
)
[3] => Array
(
[0] => チーズバーガー
[1] => チキンナゲット
[2] => コーヒー
)
[4] => Array
(
[0] => チーズバーガー
[1] => チキンナゲット
[2] => コーラ
)
[5] => Array
(
[0] => チーズバーガー
[1] => チキンナゲット
[2] => お茶
)
[6] => Array
(
[0] => てりやきバーガー
[1] => フライドポテト
[2] => コーヒー
)
[7] => Array
(
[0] => てりやきバーガー
[1] => フライドポテト
[2] => コーラ
)
[8] => Array
(
[0] => てりやきバーガー
[1] => フライドポテト
[2] => お茶
)
[9] => Array
(
[0] => てりやきバーガー
[1] => チキンナゲット
[2] => コーヒー
)
[10] => Array
(
[0] => てりやきバーガー
[1] => チキンナゲット
[2] => コーラ
)
[11] => Array
(
[0] => てりやきバーガー
[1] => チキンナゲット
[2] => お茶
)
[12] => Array
(
[0] => ビッグマック
[1] => フライドポテト
[2] => コーヒー
)
[13] => Array
(
[0] => ビッグマック
[1] => フライドポテト
[2] => コーラ
)
[14] => Array
(
[0] => ビッグマック
[1] => フライドポテト
[2] => お茶
)
[15] => Array
(
[0] => ビッグマック
[1] => チキンナゲット
[2] => コーヒー
)
[16] => Array
(
[0] => ビッグマック
[1] => チキンナゲット
[2] => コーラ
)
[17] => Array
(
[0] => ビッグマック
[1] => チキンナゲット
[2] => お茶
)
)
flatMap()で全データを加工する
例えば、全データの文字数を数えたい場合です。
$collection = collect([
['name' => '鈴木'],
['todofuken' => '東京都'],
['major' => '経営学'],
]);
$flattened = $collection->flatMap(function ($values) {
return array_map('mb_strlen', $values);
});
print_r($flattened->toArray());
これを実行すると以下のようにキーごとにカウントされた文字数が取得できます。
Array
(
[name] => 2
[todofuken] => 3
[major] => 3
)
flatten()で多次元配列を1次元配列にする
多次元配列を1次元配列に変更します。
$collection = collect([
'red' => '赤',
'others' => ['青', '黄色']
]);
$flattened = $collection->flatten();
print_r($flattened->toArray());
これを実行すると以下のようになります。
Array
(
[0] => 赤
[1] => 青
[2] => 黄色
)
※キーは保持されません。
flip()でキーと値を入れ替える
キーと値を入れ替えます。
$collection = collect([
'key_1' => 'value_1',
'key_2' => 'value_2',
'key_3' => 'value_3'
]);
$flipped = $collection->flip();
print_r($flipped->toArray());
実行結果はこうなります。
Array
(
[value_1] => key_1
[value_2] => key_2
[value_3] => key_3
)
ちなみに、以下のように値が重複している場合は最後のものが適用されます。
$collection = collect([
'key_1' => 'value_1',
'key_2' => 'value_1',
'key_3' => 'value_1'
]);
$flipped = $collection->flip();
print_r($flipped->toArray());
(実行結果)
Array
(
[value_1] => key_3
)
groupBy()でキーごとにデータをまとめる
例えば、年齢ごとにデータを分ける場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 25],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$grouped = $collection->groupBy('age');
print_r($grouped->toArray());
これを実行すると以下のようになります。
Array
(
[20] => Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 20
)
[1] => Array
(
[id] => 3
[name] => 田中
[age] => 20
)
)
[23] => Array
(
[0] => Array
(
[id] => 2
[name] => 佐藤
[age] => 23
)
)
[25] => Array
(
[0] => Array
(
[id] => 4
[name] => 山本
[age] => 25
)
[1] => Array
(
[id] => 5
[name] => 藤原
[age] => 25
)
)
)
この場合、1次元のキーが「年齢」になり、中身がゼロから始まる配列としてデータが振り分けられています。
もし、グループ化するキーを独自に変更したい場合は引数にfunction(){ ... }を使うといいでしょう。
$grouped = $collection->groupBy(function($item, $key){
return 'age-'. $item['age']; // 例:age-20
});
また、元データのキーを保持したい場合は第3引数にtrueを指定してください。
$grouped = $collection->groupBy(function($item, $key){
return 'age-'. $item['age'];
}, true);
実行結果は以下のようになります。
Array
(
[age-20] => Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 20
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 20
)
)
[age-23] => Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 23
)
)
[age-25] => Array
(
[3] => Array
(
[id] => 4
[name] => 山本
[age] => 25
)
[4] => Array
(
[id] => 5
[name] => 藤原
[age] => 25
)
)
)
keyBy()でキーごとにデータをまとめる
groupBy()と同様にキーごとにデータを配列でまとめますが、keyBy()の場合はキーごとに1つのデータしか取得できません。
つまり重複するものは最後のデータのみ取得されることになります。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 25],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$keyed = $collection->keyBy('age');
print_r($keyed->toArray());
この場合、年齢ごとにデータをまとめますが取得できるデータは重複したものを除いた3件だけです。そのため、全て取得したい場合はgroupBy()を使いましょう。
Array
(
[20] => Array
(
[id] => 3
[name] => 田中
[age] => 20
)
[23] => Array
(
[id] => 2
[name] => 佐藤
[age] => 23
)
[25] => Array
(
[id] => 5
[name] => 藤原
[age] => 25
)
)
また、groupBy()と同じく、引数にfunction(){ ... }を使って独自のキーを使うこともできます。
$keyed = $collection->keyBy(function($item, $key){
return 'age-'. $item['age']; // 例:age-20
});
map()で全てのデータに特定の加工をする
例えば、名前データに「様」をつける場合です。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
$new_collection = $collection->map(function($item, $key){
return $item .' 様';
});
print_r($new_collection->toArray());
これを実行すると以下のようになります。
Array
(
[0] => 鈴木 様
[1] => 佐藤 様
[2] => 田中 様
[3] => 山本 様
[4] => 藤原 様
)
transform()で全てのデータに特定の加工をする
map()と似ていますが、map()が新しいデータを作るのに対して、こちらは元データを加工します。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
$collection->transform(function($item, $key){
return $item .' 様';
});
print_r($collection->toArray());
実行結果はこうなります。
Array
(
[0] => 鈴木 様
[1] => 佐藤 様
[2] => 田中 様
[3] => 山本 様
[4] => 藤原 様
)
mapInto()で全ての要素を特定クラスのインスタンスにする
例えば、日付データをすべてCarbonのインスタンスにして取得する場合です。
$collection = collect(['2000-01-01', '2000-02-02', '2000-03-03']); $date_times = $collection->mapInto(Carbon::class);
これを実行すると以下のようになります。
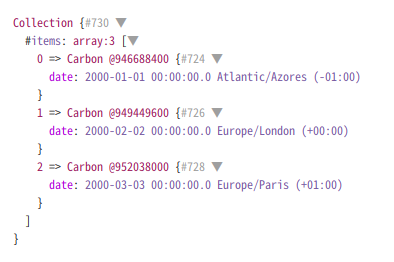
そして、もちろん独自クラスを使うこともできて、その場合はコンストラクタに各データが入ってくるようなクラス構成にする必要があります。
class Customer {
public function __construct(string $name)
{
$this->name = $name;
}
}
mapSpread()で変数に格納しながら新しいデータを作成する
多重配列になったデータを1行ずつ取り出して新しいデータを作成します。
$collection = collect([
['鈴木', '佐藤', '田中'],
['山本', '藤原', '木村']
]);
$sequence = $collection->mapSpread(function ($name_1, $name_2, $name_3) {
return $name_1 .' & '. $name_2 .' & '. $name_3;
});
print_r($sequence->toArray());
これを実行すると以下のようになります。
Array
(
[0] => 鈴木 & 佐藤 & 田中
[1] => 山本 & 藤原 & 木村
)
mapToGroups()で1行ずつ取得しながらグループ化する
例えば、年齢ごとにグループをつくる場合です。
groupBy()でも同じことができますが、mapToGroups()の場合は同時に各データにいろんな加工をすることができます。
実際の例を見てみましょう。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 25],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$grouped = $collection->mapToGroups(function ($item, $key) {
$age = 'age-'. $item['age']; // 例: "age-20"
$name = $item['name'] .' さん'; // 例: "鈴木 さん"
return [$age => $name];
});
print_r($grouped->toArray());
実行結果はこうなります。
Array
(
[age-20] => Array
(
[0] => 鈴木 さん
[1] => 田中 さん
)
[age-23] => Array
(
[0] => 佐藤 さん
)
[age-25] => Array
(
[0] => 山本 さん
[1] => 藤原 さん
)
)
returnするのが連想配列になっていることに注意してください。
mapWithKeys()で連想配列をつくる
例えば、あるデータから特定の連想配列を作成する場合です。mapToGroups()と似ていますが、こちらはキーが重複する場合は上書きされます。(つまり1つのキーには1つの値しか保持できない)
では、例を見てみましょう。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 23],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 25],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$grouped = $collection->mapWithKeys(function ($item) {
$age = 'age-'. $item['age'];
$name = $item['name'] .' さん';
return [$age => $name];
});
print_r($grouped->toArray());
実行結果はこうなります。(20歳と25歳が重複しているので、全部で3件だけです)
Array
(
[age-20] => 田中 さん
[age-23] => 佐藤 さん
[age-25] => 藤原 さん
)
pad()でデータ数を揃える
例えば、値が3つあるCollectionを5つに揃えたい場合です。
$collection = collect(['鈴木', '佐藤', '田中']); $new_collection = $collection->pad(5, '(欠席)'); print_r($new_collection->toArray());
上の例では、データ数は3つなのに対してpad()では5つになるよう指定してます。そのため、足りない文のデータは「(欠席)」が追加されます。
Array
(
[0] => 鈴木
[1] => 佐藤
[2] => 田中
[3] => (欠席)
[4] => (欠席)
)
partition()で2グループに分ける
例えば、テストで80点以上取った点数と、そうでない点数を分ける場合です。
$collection = collect([80, 73, 60, 98, 22]);
list($pass, $fail) = $collection->partition(function($score){
return ($score >= 80);
});
print_r($pass->toArray());
print_r($fail->toArray());
実行結果はこうなります。
Array
(
[0] => 80
[3] => 98
)
Array
(
[1] => 73
[2] => 60
[4] => 22
)
※キーが保持されていることに注意してください。
pipe()でCollectionをfunction()へ送り返り値を受け取る
$collection = collect(['id' => 1, 'name' => '鈴木', 'age' => 20]);
$piped = $collection->pipe(function($collection) {
return $collection->get('age');
});
print_r($piped);
skip()で指定の数だけ飛ばしてデータを取得する
例えば、「あ、い、う、え、お」から「あ、い、う」を飛ばして「え、お」だけを取得する場合です。
$collection = collect(['あ', 'い', 'う', 'え', 'お'])->skip(3); // 3つ飛ばしたデータ print_r($collection->toArray());
※このメソッドは内部にはslice()が呼ばれていますが、slice()のように第2引数は受け付けません。
Laravel 6.x 以降
slice()でデータを抜き出す
例えば、3番め以降のデータだけ抜き出す場合です。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $slice = $collection->slice(2); // 0から始まる数字。ここ以降が残る print_r($slice->toArray());
これを実行するとこうなります。
Array
(
[2] => 田中
[3] => 山本
[4] => 藤原
)
※キーが保持されていることに注意してください。
また、第2引数で件数を指定することもできます。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $slice = $collection->slice(2, 2);
結果こうなります。
Array
(
[2] => 田中
[3] => 山本
)
splice()でデータを抜き出す
slice()と似ていますが、splice()は元データを該当するデータを削除し、その削除したデータを元に新しいCollectionを作成します。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $chunk = $collection->splice(2); // 0から始まる数字。ここ以降が削除される print_r($collection->toArray()); print_r($chunk->toArray());
実行結果はこうなります。
Array(元データ)
(
[0] => 鈴木
[1] => 佐藤
)
Array(新しいデータ)
(
[0] => 田中
[1] => 山本
[2] => 藤原
)
また、slice()と同様に第2引数で件数を指定することもできます。
$chunk = $collection->splice(2, 1);
replace()でデータを入れ替える
例えば、すでに存在しているコレクションの一部を入れ替えたい場合です。
$replaced = collect(['太郎', '次郎', '三郎'])->replace([
1 => '四郎', // 次郎 → 四郎,
3 => '五郎', // インデックス3に追加
]);
print_r($replaced->toArray());
この場合は、インデックス番号1は「次郎」なので「四郎」と入れ替わりますが、インデックス番号3は存在していないのでそのまま追加されます。
結果はこうなります。
Array
(
[0] => 太郎
[1] => 四郎 // 入れ替わった
[2] => 三郎
[3] => 五郎 // 追加された
)
Laravel 5.8.28 以降
replaceRecursive()で階層が深いデータを入れ替える
replace()と似ていますがこちらは、深い階層のデータにも対応しています。
以下の例を見てみましょう。
$replaced = collect([
'太郎',
'次郎',
['id' => 55, 'name' => '三郎']
])->replaceRecursive([
1 => '四郎', // 次郎 → 四郎,
2 => [
'id' => 99 // 55 → 99
],
]);
print_r($replaced->toArray());
この場合、インデックス番号1の「次郎」は「四郎」に置き換わり、さらにインデックス番号2のidの値が55から99へ変更になります。
結果はこうなります。
Array
(
[0] => 太郎
[1] => 四郎 // 入れ替わった
[2] => Array
(
[id] => 99 // 入れ替わった
[name] => 三郎
)
)
Laravel 5.8.28 以降
データを並べ替える
sort()で昇順に並べ替える
小さい値から順番に並べ替える場合です。
$collection = collect([80, 15, 93, 63, 25]); $sorted = $collection->sort(); print_r($sorted->toArray());
これを実行するとこうなります。
Array
(
[1] => 15
[4] => 25
[3] => 63
[0] => 80
[2] => 93
)
※キーが保持されていることに注意してください。
sortDesc()で降順に並べ替える
sort()の方向が逆のバージョンです。
詳しくは前項目のsort()をご覧ください。
Laravel 7.x 以降
sortBy()でキーを指定して昇順に並べ替える
例えば、年齢の若い順に会員データを並べ替える場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 16],
['id' => 2, 'name' => '佐藤', 'age' => 30],
['id' => 3, 'name' => '田中', 'age' => 27],
['id' => 4, 'name' => '山本', 'age' => 35],
['id' => 5, 'name' => '藤原', 'age' => 23],
]);
$sorted = $collection->sortBy('age');
print_r($sorted->toArray());
実行結果はこうなります。
Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 16
)
[4] => Array
(
[id] => 5
[name] => 藤原
[age] => 23
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 27
)
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 30
)
[3] => Array
(
[id] => 4
[name] => 山本
[age] => 35
)
)
※キーが保持されていることに注意してください。
また、sortBy()の引数にはfunction(){ ... }を使うこともできます。例えば、趣味が少ない順に並べ替える場合は以下のようになります。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'hobbies' => ['ピアノ', '読書']],
['id' => 2, 'name' => '佐藤', 'hobbies' => ['登山']],
['id' => 3, 'name' => '田中', 'hobbies' => ['ゴルフ', '料理', 'ヨガ']]
]);
$sorted = $collection->sortBy(function($item, $key){
return count($item['hobbies']);
});
print_r($sorted->toArray());
実行結果です。
Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[hobbies] => Array
(
[0] => 登山
)
)
[0] => Array
(
[id] => 1
[name] => 鈴木
[hobbies] => Array
(
[0] => ピアノ
[1] => 読書
)
)
[2] => Array
(
[id] => 3
[name] => 田中
[hobbies] => Array
(
[0] => ゴルフ
[1] => 料理
[2] => ヨガ
)
)
)
sortByDesc()でキーを指定して降順に並べ替える
sortBy()の逆バージョンです。
sortKeys()でキーの昇順に並べ替える
キーを使って昇順に並べ替える場合です。
$collection = collect([
'ccc' => 3,
'aaa' => 1,
'eee' => 5,
'ddd' => 4,
'bbb' => 2
]);
$sorted = $collection->sortKeys();
print_r($sorted->toArray());
実行結果はこうなります。
Array
(
[aaa] => 1
[bbb] => 2
[ccc] => 3
[ddd] => 4
[eee] => 5
)
sortKeysDesc()でキーの降順に並べ替える
sortKeys()の逆バージョンです。
reverse()で並び順を反転させる
データを逆順にする場合です。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $reversed = $collection->reverse(); print_r($reversed->toArray());
これを実行するとこうなります。
Array
(
[4] => 藤原
[3] => 山本
[2] => 田中
[1] => 佐藤
[0] => 鈴木
)
※順番は変わりましたが、キーは保持されていることに注意してください。
shuffle()でランダムに並べ替える
中身をランダムに並べ替える場合です。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $shuffled = $collection->shuffle(); print_r($shuffled->toArray());
(ランダムに内容は変わります)
Array
(
[0] => 藤原
[1] => 田中
[2] => 佐藤
[3] => 山本
[4] => 鈴木
)
※キーが保持されないことに注意してください。
データをチェックする
has()で特定のキーが存在するかをチェックする
例えば、年齢データ(age)が含まれているかどうかをチェックする場合です。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20
]);
if($collection->has('age')) {
echo '年齢データが含まれています。';
}
※注意が必要なのは、もし指定したキーの中身がnullや空白でも、この例ではtrueとなることです。つまり、単純にキーが存在してるかどうかをチェックしてるんですね。
contains()で特定のデータが含まれているかどうかをチェックする
指定した値が含まれているかをチェックします。
$collection = collect(['鈴木', '佐藤', '田中']);
if($collection->contains('鈴木')) {
echo '鈴木さんが含まれています。';
}
また、キーが入ったCollectionでも同様に使えます。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 25
]);
if($collection->contains('鈴木')) {
echo '鈴木さんが含まれています。';
}
そして、多重構造の場合、キーを指定してデータが含まれているかどうかをチェックすることもできます。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 22],
['id' => 3, 'name' => '田中', 'age' => 30]
]);
if($collection->contains('name', '鈴木')) {
echo '「name」に鈴木さんが含まれています。';
}
最後に、function(){ ... }を使った方法も紹介しましょう。trueになる条件式をreturnするようにします。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 22],
['id' => 3, 'name' => '田中', 'age' => 30]
]);
$result = $collection->contains(function($values, $key){
return ($values['name'] == '鈴木');
});
if($result) {
echo '鈴木さんが含まれています。';
}
some()で特定のデータが含まれているかどうかをチェックする
contains()のエイリアス、つまり同じものです。
Laravel 5.7.16 以降
containsStrict()でデータが含まれているかチェックする
基本的にはcontains()と同じですが、比較の仕方がより厳しくなっています。
実際の例を見てみましょう。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 20],
['id' => 2, 'name' => '佐藤', 'age' => 22],
['id' => 3, 'name' => '田中', 'age' => 30]
]);
if($collection->containsStrict('age', '20')) {
// この条件では「true」にならない
} else if($collection->containsStrict('age', 20)) {
// この条件では「true」になる
}
上の例ですと、ひとつ目のcontainsStrict()はfalseになります。なぜなら、指定された値が'20'と文字列として比較されているからです。
つまり、
if($a === $b) {}
が成り立つ関係でないといけません。そのためBooleanと数字の比較などを注意しておく必要があります。
every()で全ての要素が条件をクリアしてるかチェックする
例えば、「全員がテストで80点以上とってるかどうか」をチェックする場合です。
$collection = collect([80, 100, 95, 82]);
$result = $collection->every(function($value, $key){
return ($value >= 80);
});
if($result) {
echo '全員が80点以上取っています';
}
つまり、function(){ ... }内の条件式で全てがtrueになれば、$resultはtrue。逆に1つでも条件式を満たさないデータがある場合はfalseになります。
isEmpty()で中身が空かどうかをチェックする
中身が空かどうかをチェックします。
$collection = collect([]);
if($collection->isEmpty()) {
echo '中身は空です。';
}
ちなみに、以下のような配列のnullの場合は、false(つまり、空ではない)となります。
$collection = collect([null]); $collection->isEmpty(); // false:空ではないと判断される
ただし、以下のように中身自体がnullの場合は空白とみなされてtrueになります。
$collection = collect(null); $collection->isEmpty(); // true:空です
isNotEmpty()で中身が空ではないかどうかをチェックする
isEmpty()の逆バージョンです。
$collection = collect(['xxx']);
if($collection->isNotEmpty()) {
echo '中身は空ではありません。';
}
データの中身を表示する
dd()でデータの中身を表示する
データの中身を表示し、その場で処理を終了させます。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $collection->dd(); echo 'ここは実行されません';

dump()でデータの中身を表示する
dd()と同じく中身を表示してくれますが、こちらは途中で処理が終了にはなりません。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']); $collection->dump(); echo 'ここは実行されます。';
条件で分岐させる
when()で条件分岐させる
ある条件がtrueの場合に実行するメソッドです。
$boolean = true;
$collection = collect(['鈴木', '佐藤', '田中', '山本']);
$collection->when($boolean, function($collection){
// この例では実行されます
});
whenEmpty()でデータが空の場合だけ実行する
例えば、以下のように$collectionが空の場合にだけ「四郎」が追加されます。
$collection = collect(); // コレクションが空
$collection->whenEmpty(function($c){
$c->push('四郎'); // コレクションが空なので実行される
});
print_r($collection->toArray());
逆に次の場合は「四郎」が追加されることはありません。
$collection = collect(['太郎', '次郎', '三郎']); // 空ではない
$collection->whenEmpty(function($c){
$c->push('四郎'); // 実行されない
});
Laravel 5.7.13 以降
whenNotEmpty()でデータが空ではない場合だけ実行する
whenEmpty()の逆バージョンです。
Laravel 5.7.13 以降
unless()で条件分岐させる
ある条件がfalseの場合に実行するメソッドです。
$boolean = false;
$collection = collect(['鈴木', '佐藤', '田中', '山本']);
$collection->unless($boolean, function($collection){
// この例では実行されます
});
重要なのはfalseの場合に実行される点です。もしtrueの場合に実行したい場合はwhen()を使ってください。
unlessEmpty()でデータが空ではない場合だけ実行する
whenEmpty()とは逆に$collectionが空ではない場合だけ実行します。
$collection = collect(['太郎', '次郎', '三郎']);
$collection->unlessEmpty(function($c){
$c->push('四郎'); // コレクションが空ではないので実行される
});
print_r($collection->toArray());
逆に次の場合は「四郎」が追加されることはありません。
$collection = collect(); // 空
$collection->whenEmpty(function($c){
$c->push('四郎'); // 実行されない
});
Laravel 5.7.13 以降
unlessNotEmpty()でデータが空の場合だけ実行する
unlessEmpty()の逆バージョンです。
Laravel 5.7.13 以降
データを絞りこむ
where()でデータを絞り込む
例えば、データの中から20歳の人だけを絞り込む場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 16],
['id' => 2, 'name' => '佐藤', 'age' => 20],
['id' => 3, 'name' => '田中', 'age' => 27],
['id' => 4, 'name' => '山本', 'age' => 20],
['id' => 5, 'name' => '藤原', 'age' => 23]
]);
$filtered = $collection->where('age', 20);
print_r($filtered->toArray());
実行結果はこうなります。
Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 20
)
[3] => Array
(
[id] => 4
[name] => 山本
[age] => 20
)
)
whereStrict()でデータを絞り込む
where()とほぼ同じですが、比較の方法がより厳格なものになっています。つまり、以下のように型も考慮した比較をします。
if($a === $b) {}
※使い方はwhere()と同じです。
whereIn()で複数の該当データを絞り込む
例えば、20歳と23歳の会員データだけを取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 16],
['id' => 2, 'name' => '佐藤', 'age' => 20],
['id' => 3, 'name' => '田中', 'age' => 27],
['id' => 4, 'name' => '山本', 'age' => 20],
['id' => 5, 'name' => '藤原', 'age' => 23]
]);
$filtered = $collection->whereIn('age', [20, 23]);
print_r($filtered->toArray());
これを実行するとこうなります。
Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 20
)
[3] => Array
(
[id] => 4
[name] => 山本
[age] => 20
)
[4] => Array
(
[id] => 5
[name] => 藤原
[age] => 23
)
)
whereInStrict()でデータを絞り込む
whereIn()とほぼ同じですが、比較の方法がより厳格なものになっています。つまり、以下のように型も考慮した比較をします。
if($a === $b) {}
※使い方はwhereIn()をご覧ください。
whereNotIn()で指定データ以外に絞り込む
whereIn()の逆バージョンです。つまり、指定したデータ「以外」のものだけに絞り込むメソッドです。例えば、20歳と23歳「以外」の会員データを取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 16],
['id' => 2, 'name' => '佐藤', 'age' => 20],
['id' => 3, 'name' => '田中', 'age' => 27],
['id' => 4, 'name' => '山本', 'age' => 20],
['id' => 5, 'name' => '藤原', 'age' => 23]
]);
$filtered = $collection->whereNotIn('age', [20, 23]);
print_r($filtered->toArray());
実行結果はこうなります。
Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 16
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 27
)
)
whereNotInStrict()で指定データ以外に絞り込む
whereNotIn()とほぼ同じですが、比較の方法がより厳格なものになっています。つまり、以下のように型も考慮した比較をします。
if($a === $b) {}
※使い方はwhereNotIn()をご覧ください。
whereInstanceOf()でクラスのインスタンスかどうかで絞り込む
どのクラスのインスタンスかをチェックして絞り込みをしたいときに使います。
$collection = collect([
\App\User::find(1),
new \App\User,
new \App\Item,
]);
$filtered = $collection->whereInstanceOf(\App\User::class);
この例で取得できるのは、1つ目と2つ目のデータです。
whereBetween()で2つの値の間にあるデータを取得する
例えば、20〜30才のデータを取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 18],
['id' => 2, 'name' => '佐藤', 'age' => 28],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 30],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$filtered = $collection->whereBetween('age', [20, 30]);
print_r($filtered->toArray());
結果はこうなります。
Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] => 28
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 20
)
[3] => Array
(
[id] => 4
[name] => 山本
[age] => 30
)
[4] => Array
(
[id] => 5
[name] => 藤原
[age] => 25
)
)
※age >= 20、age <= 30であることに注目してください。
Laravel 5.7.19 以降
whereNotBetween()で2つの値の間は「ない」データを取得する
whereBetween() の逆バージョンです。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 18],
['id' => 2, 'name' => '佐藤', 'age' => 28],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => 30],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$filtered = $collection->whereNotBetween('age', [20, 30]);
print_r($filtered->toArray());
結果はこうなります。
Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 18
)
)
Laravel 5.7.19 以降
whereNull()でNullのデータだけ取得する
例えば、年齢がnullのデータだけを取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 18],
['id' => 2, 'name' => '佐藤', 'age' => null],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => null],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$filtered = $collection->whereNull('age');
print_r($filtered->toArray());
結果はこうなります。
Array
(
[1] => Array
(
[id] => 2
[name] => 佐藤
[age] =>
)
[3] => Array
(
[id] => 4
[name] => 山本
[age] =>
)
)
Laravel 6.15 以降
whereNotNull()でNull「以外」データだけ取得する
例えば、年齢がnull「以外」のデータだけを取得する場合です。
$collection = collect([
['id' => 1, 'name' => '鈴木', 'age' => 18],
['id' => 2, 'name' => '佐藤', 'age' => null],
['id' => 3, 'name' => '田中', 'age' => 20],
['id' => 4, 'name' => '山本', 'age' => null],
['id' => 5, 'name' => '藤原', 'age' => 25],
]);
$filtered = $collection->whereNotNull('age');
print_r($filtered->toArray());
結果はこうなります。
Array
(
[0] => Array
(
[id] => 1
[name] => 鈴木
[age] => 18
)
[2] => Array
(
[id] => 3
[name] => 田中
[age] => 20
)
[4] => Array
(
[id] => 5
[name] => 藤原
[age] => 25
)
)
Laravel 6.15 以降
その他
macro()で独自のCollectionメソッドをつくる
独自のCollectionメソッドを作りたい場合です。
実際の例を見てみましょう。
名前の後に「様」をつける独自メソッドsir()です。
Collection::macro('sir', function($key){
return $this->get($key) .' 様';
});
やっていることは、第1引数にメソッド名、第2引数に独自データを返すfunction(){ ... }を設定しているだけです。(どこからでも呼び出せるようにAppServiceProvider.php にでも記述すればいいでしょう)
使い方はこうなります。
$collection = collect([
'id' => 1,
'name' => '鈴木',
'age' => 20
]);
echo $collection->sir('name'); // 鈴木 様
make()でCollectionをつくる
新しいコレクションを作成します。
$collection = Collection::make(['鈴木', '佐藤', '田中', '山本', '藤原']);
ただ、個人的にはコード量が少ないヘルパー関数collect()を使うことをおすすめします。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
tap()で途中経過をチェックする
Collectionの構造をいくつか変化させる途中で「データがどうなっているか」をチェックする場合に使います。
$collection = collect(['鈴木', '佐藤', '田中', '山本', '藤原']);
$collection->sort()
->tap(function($collection){
// 並べ替えた直後の状況をチェック
print_r($collection->toArray());
})
->shuffle();
おわりに
当初はそれほどこの記事を作成するのに時間がかかるとは思ってませんでしたが、結果として(フルではないにしても)3日ほど時間がかかり最終的に4万文字を越えることになってしまいました。^^;(追記で5万文字を超えました😅)
ただ、新しい発見をたくさん発見したので開発者としてはプラスになったと思います。
みなさんも時短&可読性の良いコードのためにぜひ参考にしてみてくださいね。
ではでは〜。
 さすがにちょっと疲れました・・・zzz
さすがにちょっと疲れました・・・zzz





